腾讯旗下的图像技术团队—优图团队,近日在国际著名深度学习开源框架Cuda-Convnet2项目上做出了重要的代码提交,将其GPU训练性能提升50%之多,显示了腾讯在深度学习领域的又一重大进展及腾讯积极参与开源项目与业界共享技术研究进展的开放心态。
近年来,深度学习及相关领域已然成为最活跃的计算机研究领域之一,无论是学术界还是互联网科技巨头,均在此方向投入了巨大的研究资源。深度学习在计算机视觉、语音识别等领域均带来了巨大的、非常领先的研究成果。但由于其超级庞大的网络计算规模和海量的训练数据,深度学习的训练往往耗时巨大,已经成为深度学习目前研究和实践中一个巨大瓶颈。腾讯优图团队在GPU kernel层面做了大量底层优化工作,极大缓解了深度学习训练性能这个瓶颈。
优图团队的优化工作主要基于Alex Krizhevsky实现的CUDA-Convnet2框架。Alex Krizhevsky是深度学习领域非常有影响力的研究者之一,是著名的AlexNet模型的发明者。CUDA-Convnet2模型是一种支持多GPU并行运行的深度学习算法框架,是所有同类开源框架中性能最优秀的框架。
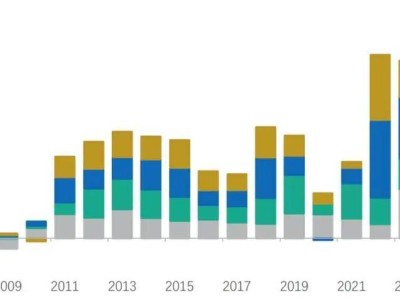
优图团队的深度学习系统在CUDA-Convnet2的基础上,实现了更为高效的GPU利用。测试结果表明(如图表1所示),batchSize为32或64时,优化后的内核速度提升超过50%,这也弥补了之前CUDA-Convnet2在batchSize 32或64时的不足。batchSize为128时,内核速度有10%以上的提升,在对jpeg解码部分做优化后,整体性能提升也达到50%。

图表 1 优图优化前后的性能对比
之所以取得如此大的进展,是因为优图团队在精通GPU硬件架构和深度学习算法的基础上,采用了更加前沿的优化策略。优图团队的优化理念源自于当前的GPU计算主频已足够高,而数据访问速度跟不上运算速度,造成GPU的空转。其优化点主要包含如下几点:
1. 更大的共享内存带宽。现在的GPU都具有高达64~128 bit的共享内存带宽,且共享内存具有访问速度快等特点。为了充分利用共享内存的硬件性能,优图团队采用矢量化的数据类型来匹配更大的内存带宽,使得数据的访问速度呈倍数增加,极大提升了数据的传输速度;
2. 巧妙的数据拓扑结构和精心组织的访问指令顺序。由于大部分GPU都支持并发访问的特性,为了进一步提升内存访问速度,优图团队巧妙的排列数据拓扑结构和数据访问指令顺序。众所周知,页面冲突是内存并发访问的最大的难题,因此,通过巧妙的排列数据结构可以最大程度减少页面冲突,提升并发访问的几率。同时在充分利用指令集的并发流水线基础上,优化数据的访问指令顺序,提升指令间并行度,也可以大幅提升数据访问速度;
3. 高效的数据传输粒度。由于GPU程序分为运算和数据访问两个部分,当数据访问速度跟不上GPU的运算速度时,为了最大程度利用GPU性能,应尽量避免GPU的运算部分或数据访问部分处于长期空转的状态,因此必须优化数据的访问粒度。将过大的数据访问粒度切割成若干个小的访问粒度,合适插入到GPU的运算周期中。
腾讯优图团队长期致力于各种图像技术和深度学习方向的研究和应用。在人脸检测和人脸识别,图像美化和人像美容等方向上均有深厚的积累并取得了业内领先的成果。此次深度学习性能优化的重要进展和开源贡献相信能够为业界在深度学习的研究上提供非常有益的帮助。