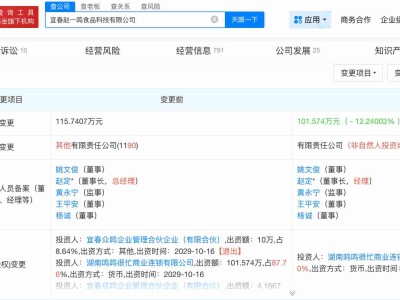
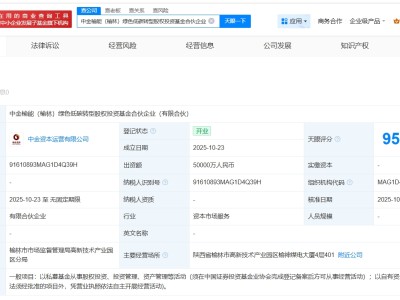
如今的技术开发成果已经让人印象深刻,计算机可以辨识图片和视频里的东西,可以将语音转化成为文字,其效率已经超过了人力范畴。Google也将GoogleTranslate服务中添加了神经网络,现在的机器学习在翻译水平上已经逐步逼近人工翻译。现实中的一些应用也让人大开眼界,比如计算机可以预测农田作物产量,其准确性比美国农业部还高;机器能更加精准的诊断癌症,其准确度也比从医多年的老医师还要高。
深度学习在当下已经成为热词,人工智能教育践行者叶伟志认为虽然深度学习的成果不断涌现,但深度学习目前还存在着很多问题,任重而道远。
一 、 现在 的 机器学习缺乏交互学习的能力
现在一个深度学习的模型,如果拿到一个新的数据集上训练一遍,它会把原来在老数据集上训练的东西全部忘掉。这里需要一种学习能力是自主学习,我们需要这个机器能够自己去寻找具有价值的一些数据和状态。
第二种学习方式叫做交互式学习,人类在学习的时候,除了我们自己去观察这个世界,总结规律以外,很多的学习来源于和人的交互中得到。
还有一种重要的学习方式是创造性学习,人的智力的核心是具备自己学习和自我创造的能力,现在的机器学习,在这方面非常缺乏。
二 、现在的机器 缺乏常识
一个典型的例子是自动驾驶,学过开车的都知道,从开始学到能够熟练的开车,可能有几百公里的驾驶路程就可以了,谷歌的无人车到目前为止已经开了几百万公里,还是做不到无人完全自动驾驶。其中最主要的一个原因,它不像人类具备一些常识性的推理能力。
这导致的后果是它需要研究人员或工程师,在每一种可能遇到的路况都要做特定的处理,需要在它这几百万公里的数据里面,尽量的覆盖可能多的交通状况和路况。即便如此,它还是不能够保证能处理遇到的一些新路况。人类学习开车,主要学的是控制方向盘和踩油门,针对前方路况是要开过去还是减速,人类通过常识就可以做到。
三 、 现在 的 机器学习很难从少量的标注数据进行学习
比如ImageNet比赛,每一幅图,机器平均有上千个样本来学习。而对于人类,要学习识别一个新的物体,给他看一两眼大概就能学会了。
怎么样才能够有效的利用少量的标注数据进行学习呢?其中重要的一点就是我们需要有非常好的特征表示,好的特征表示需要有大量的数据才能学到,而大量没有标注的数据,则需要通过非监督的方式才能有效的把里面的特征表示很好的学习出来。
怎么样做到非监督学习呢?就是通过对未来的预测进行非监督学习。能够对未来做出预测是智力一个非常核心的部分。物理学是对一个简单系统比较精确的预测,而深度学习或者人的智力是对一个复杂系统近似的预测。如果我们能够对未来进行一个比较好的预测,那就说明这个模型能够抓住环境,以及变化的本质规律,从而能够提取出一些比较有用的信息,这样能够有效的把它用于少量的标注数据的学习。
四 、现在 的很多成功应用是基于标注好的一些标注数据来学习
对于人类来说,如果要辨别两只鸟,我们学习的过程就是,根据以前人类的知识,总结出两只鸟尾巴长短会的不同,以前的经验还会总结出这两种鸟的头部斑纹的不同。人类在接受了语言的描述,知识和经验的累积,可以非常快的学习。现在机器还没有办法把人通过语言来传递的这种知识和标注数据,有机的结合进行学习。
叶伟志,壹企问咨询总经理,广东天使会合伙人,人工智能企业应用专家,资深软件开发工程师。