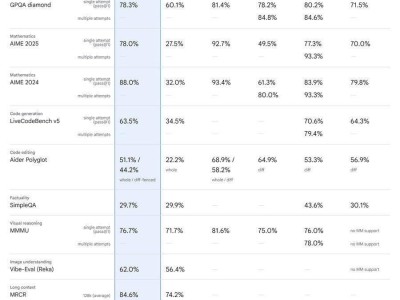
近日,哈工大讯飞联合实验室发布了基于全词覆盖的中文 BERT 预训练模型,该模型在多个中文数据集上,取得了当前中文预训练模型的最佳水平,部分效果甚至超过了原版 BERT、ERNIE等中文预训练模型。。
这一新的模型资源,极大地推动了中文自然语言处理的研究发展,弥补了之前该研究模型在中文自然语言处理上的空缺。之前 ERNIE 更多使用百度百科、贴吧等网络数据,它对非正式文本(例如微博等)建模较好,而BERT-wwm使用了中文维基百科(包括简体和繁体)数据进行训练,故此对正式文本建模更有优势,同时BERT-wwm也能更好的处理繁体中文数据,因为 ERNIE 的词表中几乎没有繁体中文,让业界多了一个选择。

哈工大讯飞联合实验室(HFL)是科大讯飞重点引进和布局的核心研发团队之一,由科大讯飞AI研究院与哈尔滨工业大学社会计算与信息检索研究中心(HIT-SCIR)在2014年共同创办。
自哈工大讯飞联合实验室成立,双方一直进行着深入地合作,特别是语言认知计算领域,成果显著,研究涉及阅读理解、自动阅卷、类人答题、人机对话、语音识别后处理、社会舆情计算等前瞻课题,相应研究成果应用于司法,教育等领域。哈工大讯飞联合实验室在近几年获得多项世界冠军,其中包括机器阅读理解权威评测SQuAD、SQuAD 2.0,第五届中文语法错误自动诊断大赛CGED,对话型阅读理解评测CoQA、QuAC等。
此次发布的基于全词覆盖的中文BERT,不仅表明科大讯飞在自然语言处理技术上保持业界领先水平,同时还积极将最新技术转化应用到中文自然语言处理的研究中,与业界一同推进中文自然语言处理的研究与发展,为中文信息处理做出更多贡献。
AI蓬勃发展,人工智能要求的是不仅要“能听会说”,还要“能理解会思考”,这一技术跨越,需要大量科学研究的支持。深层语义理解、逻辑推理决策、自主学习进化等认知智能的关键技术,都是当下的研究重点。语音合成技术、语音识别技术、手写识别技术、自然语言处理技术、语音测评技术、声纹识别技术,这些技术都展现出了讯飞的超强实力。

科大讯飞一直将“顶天立地”作为企业的核心使命。“顶天”,即技术顶天,强调技术对AI发展的的重要性。科大讯飞长期对科研保持着高投入,据其2018年财报显示,2018年公司新增相关研发费用4.52亿元,相关研发费用总额达12.63亿元,较上年同期增长55.82%。科研投入可谓相当之大,难怪其技术可以一直保持行业领先了。
科大讯飞还是目前我国唯一以语音技术为产业化方向的“国家863计划成果产业化基地”、“国家规划布局内重点软件企业”、“国家高技术产业化示范工程”, 曾两次荣获“国家科技进步奖”及中国信息产业自主创新荣誉“信息产业重大技术发明奖”。科技部明确依托科大讯飞建设了认知智能国家重点实验室,这是我国在人工智能高级阶段——认知智能领域的第一个国家级重点实验室。
领先的技术以及对整个人工智能生态产业的全面把控上,科大讯飞向人们展现出了它的长远眼光。其构建的国内首个以智能语音和人机交互为核心的人工智能开放平台——讯飞开放平台,并基于该平台相继推出讯飞输入法、讯飞听见等示范性应用,推动与广大合作伙伴携手构建以讯飞为中心的人工智能产业生态。其在智能语音和人工智能核心研究和产业化方面的突出成绩,也得到了社会各界和国内外的一致认可,被称为“中国人工智能国家队”。
对技术的不断追求,对科研的不断精进,对用户的细微关注,是每一个希望大力发展AI的企业都应该学习的,如今的科大讯飞, 仍在以高速不断迈进和发展,我们希望在未来,能够看到科大讯飞一个又一个技术上的突破,引领中国AI技术继续前行。
附 中文全词覆盖BERT官方资源地址https://github.com/ymcui/Chinese-BERT-wwm