
导读:物易云通目前已成为国内产融供应链运营服务平台的领军企业之一,平台年交易额超过 200 亿元,随着公司业务的快速发展,对数据计算分析的时效要求也越来越高。经数据团队的调研对比,于 2021 年引入了 Apache Doris 作为实时数据仓库。实战过程中获得一些经验,在此分享给大家。
作者|物易云通/司机宝大数据负责人 吴凡
业务背景
武汉物易云通网络科技有限公司成立于 2015 年 6 月,总部位于湖北省武汉市东湖高新区。作为国内产业互联网的探索先行者,公司致力于将产业互联网思维与新一代信息技术深化应用于煤炭、建筑、再生资源三大业务领域,以标准化、场景化、数字化的供应链综合服务解决能力,开创互联网化的“供应链技术+物流服务+金融场景”的产融协同新生态。目前公司已成为国内产融供应链运营服务平台的领军企业之一,平台年交易额超过 200 亿元。公司入选 2020 年中国互联网企业综合实力 100 强,2021 年武汉市软件收入第一名。
随着公司业务的快速发展,对数据计算分析的时效要求也越来越高。之前的产品已经无法应对庞大的数据量,为解决这一问题,数据团队通过调研对比,在 2021 年引入了 Apache Doris 作为实时数据仓库。基于 Apache Doris 建设实时数仓的过程中,沉淀了许多经验,借此机会分享给大家。
数仓架构演进
公司创业之初,是使用 MySQL 作为 BI 仓库,每天增量卸数后导入,通过定时调度存储过程进行计算。该方案能快速满足公司的跨库数据关联计算的需求,但是随着业务发展,数据和任务不断增多,MySQL 已难以支持,另外该方案局限性比较大,如果业务表存在物理删除或者没有数据更新时间的情况下,则会导致数据不准。
为了解决上述问题,我们搭建了一套 CDH 作为数据仓库。通过 Canal 订阅 MySQL 的 Binlog 到 Kafka,进行编写消费程序,将数据写入 Hbase,然后增量合并到 Hive 中,通过 Oozie 调度计算脚本。
然而离线 T+1 的数据只能满足一部分的业务需求,因此我们需要一套能快速查询实时数据的数据仓库,同时可以支持离线需求和实时需求,经过许多产品的调研对比,证明 Apache Doris 可以很好地实现我们的业务需求。
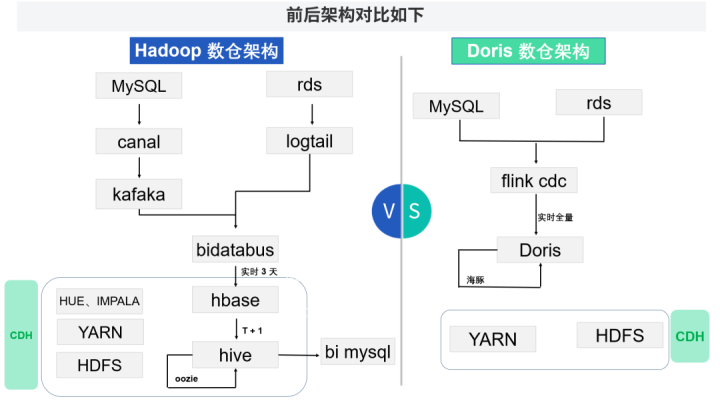
架构方案对比
Doris 数仓架构通过 Flink CDC 实时接入生产库数据到 Doris,支持实时 OLAP,然后通过海豚调度器定时执行 SQL 脚本,替代 Hive 的离线数据计算任务。
新架构的优势
1、数据处理架构简单
新的架构里我们使用了 Flink CDC 来做数据同步(Flink CDC 内置了一套 Debezium 和 Kafka 组件,但这个细节对用户屏蔽),它不但可以读取增量,还能读取全量数据,然后将数据通过 Stream load 的方式写入 Doris。
2、一份数据,实时全量
由于 Hive 查询很慢,所以之前是把 Hive 的数据通过 Sqoop 推送到 MySQL 进行查询,即有多份数据存储在不同的 MySQL 上,维护和存储成本都很高,并且 Hive 里只有 T-1 的数据,需要每天写脚本合并。Doris 支持 MySQL 协议,可直接查询,同时 Doris 支持主键数据去重及更新,有实时的全量数据,解决了实时报表和在线 OLAP 的需求。
3、架构简单,易于部署维护
相对于 Hadoop 那一套各种组件来说,Doris 部署维护非常简单。
4、一键全库接入,结构实时同步
通过自研的数据易平台,实现了 MySQL 一键全库接入 Doris,即通过页面选择后,一键生成 Flink CDC 任务在 Yarn 上持续运行。而且通过解析 Binlog 里面的 DDL 语句,将其转化为 Doris 语法,利用 Doris 的 online Schema Change 特性,实时同步生产数据库的表结构变更,保障了表结构一致,新增字段数据一致。
5、秒级查询
Doris 查询是秒级,Hive 是分钟级,跑批的效率提升了 20-30 倍。而之前用的是 Impala 加速 Hive 的查询,每个表在使用前都要 Refresh 一次,非常麻烦,并且 Count Distinct Impala 近似计算不准确。
系统重点功能
数据接入
第一步:选择需要接入的 MySQL 库类型,默认是 A,即最常见的全局库名唯一。

另外还存在几种其他的情况:
B、全局有多个名称相同、结构不一致的数据库。比如:部分大表做了数据切割归档到另一台机器上了。 C、全局有多个名称相同、结构一致的数据库,即分库。我们需要将数据合并到一个 Doris 库表中,方便数据分析。 D、全局有多个名称不同、结构一致的库。比如:DB_租户 A 的库, DB_租户 B 的库,我们也是要把数据合并分析。
第二步,选择 MySQL 库实例,进行提交(如果不想接入全库,可以勾选部分表)。对应的目标数据库是 Doris 里面的 ODS 贴源层,和生产数据保持一致,一个库一个任务,可以视情况调整内存等参数。
注意:通过列表可以进行任务管理,恢复任务是运用了 Flink CDC 的 Checkpoint 机制,在任务异常挂掉时可以恢复运行。Flink CDC 任务目前是运行在 Yarn 上。
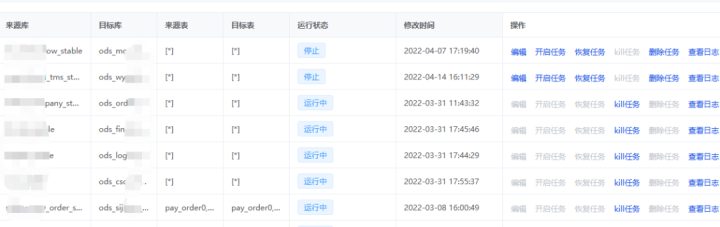
数据计算
我们在数据易平台上开发了数据计算任务功能,用户编写 SQL 后,点击 SQL 解析,即可自动识别出脚本里用到了哪些来源表,生成了哪些结果表,最终在海豚调度器里生成对应的任务和上游任务 Depend 关系。
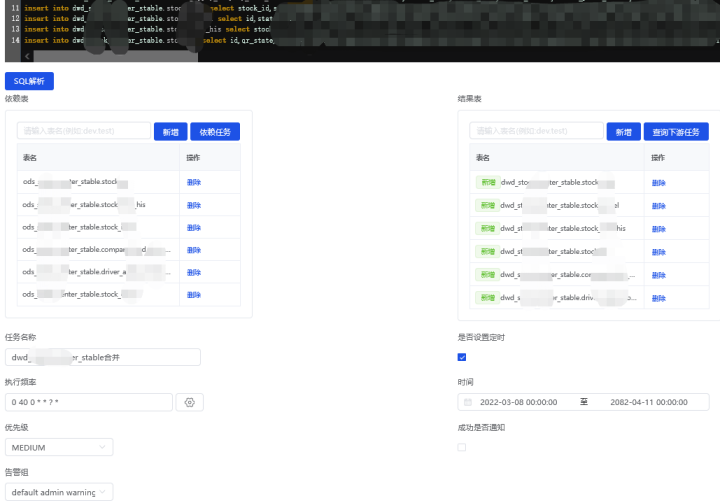
说明:为了保障各个 T+1 报表的数据一致性,我们做了 ODS 层到 DWD 层的一套计算任务,即每天 0 点将 ODS 层中近 2 天的增量数据 insert into 到 DWD 层进行更新,后续 T+1 的计算任务统一从 DWD 层进行计算。
注意:需要把物理删除变成逻辑删除,使用时剔除。如果直接在 ODS 里面同步物理删除,会导致 DWD 层里无法通过增量方式同步删除。
新架构的收益
降低资源成本
当前我们的集群配置为 5 台阿里云 ESC,16 核 64G。在相同集群配置下,1000 个表的每日增量数据合并任务,用 Hive 需要 3-5 小时,用 Spark 需要 2-3 小时,然而同样的需求 Drois 运用 Unique Key 模型完成只需要 10 分钟,大大提前了后续计算任务的开始时间。
另外,因 Hive 跑得慢,我们后续的几百个 Hive 计算任务,排队情况很严重,不得不把一些优先级低的任务排到下午甚至晚上,日任务全部跑完需要十几个小时。而我们把全部批任务迁移到 Doris 上计算后,全部任务跑完只需要 2 小时不到,后续增加新的需求任务完全无压力。
总而言之,使用 Doris 后,报表数据的更新时间大大提前,临时的数据查询需求响应时长大大缩短,至少节约了每年几万的大数据集群扩容成本,同时获得了各部门的认可。
提升开发效率
随着公司业务快速的发展,会不断的有新的数据分析需求,就需要我们接入新库新表,给老表加字段等,这对于 Hive 数仓是非常痛苦的,表要重建、全量数据要抽,这就需要每周有半天时间都在处理这些事情。
在使用 Doris 作为数仓后,通过我们的数据易平台配置 Flink CDC 任务快速接入 MySQL 库表的全量+增量数据,同时利用 Doris 的 online Schema Change 特性,实时同步 Binlog 里的 DDL 表结构变更到 Doris,数据接入数仓零开发成本。
另外因为 Doris 支持 MySQL 协议直接对接数据可视化应用,我们不需要再把结果数据从 Hive 推到 MySQL 里提供数据服务,节约了数据库资源,减少了开发步骤。
体现数据价值
Doris 有审计日志,我们可以通过日志,分析出每个表每天的查询使用情况,以便我们评估跟进数据价值、下线废弃报表及任务。另外还可以预警资源消耗多、查询慢的查询语句,帮助用户进行语法优化等。
问题与经验
1、MySQL 和 Doris 字段类型不一致
MySQL 的 Blob、Mediumint、Year、Text 等字段类型在 Doris 中没有,需要我们转换成 Doris 对应的字段类型,Varchar 的长度我们对应在 Doris 需扩大成 3 倍。
2、MySQL DDL 语法兼容性问题
MySQL 的 Bigint Unsigned、AUTO_INCREMENT、CURRENT_TIMESTAMP 等语法在 Doris 里不支持。
3、多个大表 Join 计算时,内存使用过大,导致 BE 挂掉,影响数据写入。
目前 Doris 新版本已对内存控制这部分进行优化。
4、Hive 和 Doris 差异
将 Hive 计算脚本改成 Doris 计算脚本时遇到一些语法问题,如:
Doris 不支持 Lateral View ,升级新版本已解决。
之前的一些 Hive UDF 函数是 Java 写的,Doris 不支持,我们用另外的程序对数据做的二次加工处理,后续 Doris 新版本会支持。
Doris 缺少一些函数,如 Last_Day 通过取日期下个月的第一天再减一天来实现, Collect_Set 通过先去重再 Group_Concat 实现等。
5、分析函数问题
分析函数 XX() over(partition by) 在外层和子查询中同时存在时,报 errCode = 2, detailMessage = can't support。我们通过将子查询数据放入临时表解决该问题,后面 Doris 1.0 版本已解决该问题。
多个 lag PARTITION by 函数和 min PARTITION by 一起使用时,有乱码的情况。撰文时该 Bug 已修复,等待合并发版。
6、Doris 动态分区
动态分区字段必须为 Date 到月、周、日,不能根据写入的数据自动创建分区,目前我们通过建表时指定初始化的分区数解决此问题。
7、Stream Load 写入过于频繁报错
Stream Load 写入 Doris,写入太频繁会报错误码 235 问题,同样的表 Routine Load 不会出现这个问题,我们通过批量提交解决,Doris 新版本已优化该问题。
以上问题在向社区反馈后,得到了社区的快速响应。截止目前,上述问题基本上都已经得到修复,并且将在即将发布的新版中上线。
写在最后
首先感谢 Apache Doris 社区的 PPMC 张家锋和多个 Committer 的大力支持,有任何问题都能很快得到响应。也感谢公司领导对我们方案的认可和支持,做技术改造不仅要花费很多金钱和精力,而且还需改变的勇气和坚定的信念。也感谢各位同行在使用 Apache Doris 上给了我们很多经验和信心。最后祝愿 Apache Doris 社区发展越来越好!

SelectDB 是一家开源技术公司,致力于为 Apache Doris 社区提供一个由全职工程师、产品经理和支持工程师组成的团队,繁荣开源社区生态,打造实时分析型数据库领域的国际工业界标准。基于 Apache Doris(incubating)研发的新一代云原生实时数仓 SelectDB,运行于多家云上,为用户和客户提供开箱即用的能力。
相关链接:
SelectDB 官方网站:
https://selectdb.com (We Are Coming Soon)
Apache Doris 官方网站:
http://doris.incubator.apache.org
Apache Doris Github:
https://github.com/apache/incubator-doris
Apache Doris 开发者邮件组:
dev@doris.apache.org




















