近日,OPPO小布助手团队和机器学习部联合完成了十亿参数模型“OBERT”的预训练,业务上取得了4%以上的提升;在行业对比评测中,OBERT跃居中文语言理解测评基准CLUE1.1总榜第五名、大规模知识图谱问答KgCLUE1.0排行榜第一名,在十亿级模型上进入第一梯队,多项子任务得分与排前3名的百亿参数模型效果非常接近,而参数量仅为后者的十分之一,更有利于大规模工业化应用。

CLUE1.1总榜,共9个子任务
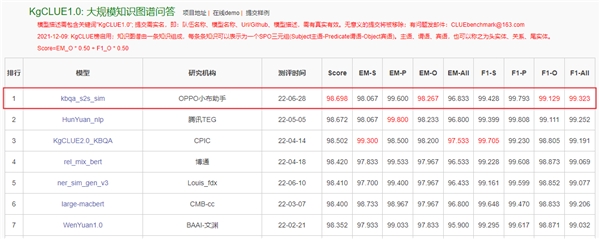
KgCLUE1.0,知识图谱问答榜
技术全自研,小布推动十亿级预训练大模型落地
大规模预训练模型的出现,为自然语言处理任务带来了新的求解范式,也显著地提升了各类NLP任务的基准效果。自2020年,OPPO小布助手团队开始对预训练模型进行探索和落地应用,从“可大规模工业化”的角度出发,先后自研了一亿、三亿和十亿参数量的预训练模型OBERT。

预训练模型开发&应用方案
得益于数据获取的低成本性和语言模型强大的迁移能力,目前NLP预训练主流的任务是基于分布式假设的语言模型。在此,小布助手团队选择了在下游自然语言理解类(NLU)任务上有更好效果的MLM,并采用课程学习作为主要预训练策略,由易到难循序渐进,提高训练稳定性。首先在一亿级模型上验证了以上mask策略的有效性,其Zero-shot效果显著优于开源base级模型,下游应用时也取得了收益,随后将其应用到十亿级模型训练中。
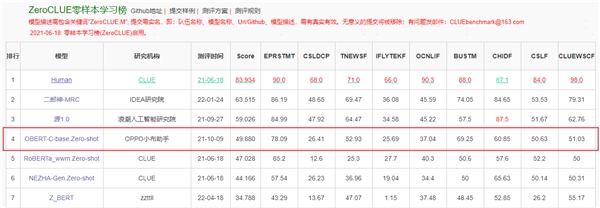
ZeroCLUE榜单
值得一提的是,从开源工作实验结果来看,语料的数量和内容多样性越大,下游任务效果会随之提升。基于前期的探索和尝试,十亿级OBERT模型清洗和收集了1.6 TB级语料,通过5种mask机制从中学习语言知识,内容包含百科、社区问答、新闻等,场景涉及意图理解、多轮聊天、文本匹配等NLP任务。
加强应用创新,小布持续深耕NLP技术
CLUE(中文语言理解评测集合)榜单是中文领域最具权威的自然语言理解榜单之一,开设了包括分类、文本相似度、阅读理解、上下文推理等共10个子任务,旨在推动NLP训练模型技术的不断进步和突破。
NLP(自然语言处理)技术被誉为人工智能皇冠上的明珠。作为人工智能认知能力的核心,NLP是AI领域最具挑战的赛道之一,其目的是使得计算机具备人类的听、说、读、写等能力,并利用知识和常识进行推理和决策。
小布助手发布于2019年,到2021年底,它已经累计搭载2.5 亿设备,月活用户数突破1.3 亿,月交互次数达20 亿,成为国内首个月活用户数破亿的手机语音助手,一跃成为国内新一代智能助手的代表。

在NLP技术方面,小布助手经历了从规则引擎、简单模型到强深度学习,再到预训练模型几个阶段。历经3年的发展,小布助手在NLP技术领域已达到行业领先水平,此次OBERT位列CLUE 1.1总榜前五、KgCLUE 1.0排行榜榜首,便是小布助手技术沉淀与积累的最好力证。
登榜CLUE 1.1总榜并登顶KgCLUE 1.0排行榜,主要得益于三个方面:一是利用小布助手积累的海量数据,获得口语化的语言数据,促进算法模型对智能助手场景的语言有更好的理解;二是保持着开放的成长型心态,跟进学术界和工业界最新的进展并加以实践;三是坚定地在最新预训练模型方向进行投入,一点一点地去做技术积累,一次一次地探索落地应用。
未来,小布助手团队会结合智能助手场景特点,持续优化预训练技术,深耕NLP,利用模型轻量化等技术加速大模型落地,并持续探索AI与主动情感的结合,让智能更人性化,在万物互融的时代,助力推动AI大放异彩,帮助AI润物细无声地融入人们未来的数智生活。