
近日,QCon全球软件开发大会在广州举办。QCon全球软件开发大会是由极客邦科技旗下 InfoQ 中国主办的综合性技术盛会,大会举办至今,已经有阿里巴巴、Google等来自国内外头部知名科技公司数万名资深工程师进行过技术分享。深信服工程技术部AI研发平台负责人孟宾宾受邀参加大会,并在现场带来《数算工程一体化机器学习开发平台助力AI算法敏捷开发》的主题演讲。本次演讲重点分享了深信服AI平台团队多年AI研发的实战经验。以下是他的演讲内容摘要。

机器学习平台建设背景介绍
深信服的AI技术主要是应用在网络安全和云计算两大业务中。在网络安全方面,AI能力会应用在病毒文件检测和家族分类、Web对抗攻击、威胁情报、数据分级分类等产品中。在云计算方面,像桌面云视频画面的增强、托管云平台故障智能预测和性能诊断与优化、边缘云的安全生产视频监控分析等场景也会用到AI。

针对不同的安全数据分析任务,并结合不同的模型部署场景,机器学习平台会涉及到非常复杂的特征工程和AI算法工程化开发。
深信服AI算法研发的过程,可以抽象成这样一个典型研发范式,业务上从网络安全和云计算两个维度来看,都会涉及到对接海量业务数据,比如说网络流量、系统日志、各种恶意文件以及云平台的运维日志。中间要经过业务强相关的特征提取,或者基于自动编码器、Graph Embedding、Word2Vec等技术自动的特征提取。最后考虑基于云端、PC端或者边缘计算设备端,高效地将算法部署运行起来。

深信服AI技术研发,主要面临数据、算法、算力这三大核心挑战。

第一个挑战是AI数据层面。深信服AI研发面临首要问题是业务数据孤岛比较多,不同的细分的业务,会有自己独立的数据存储系统。算法工程师想获取这些研发的数据,面临的阻碍会比较大,获取研发数据的时间长。其次,算法工程师取到的这些数据,因为要做精细化的特征工程,但是现在企业内部缺少比较高效地能够去管理这些中间特征以及一些高价值数据的支撑工具,导致它的数据很难被算法工程师二次使用以及被相关性比较高的任务复用起来。
第二个挑战是AI算法层面。首先表现在AI算法针对业务人员,有一定的开发门槛,并且专业算法工程师的数量是有限的,这样就无法扩大AI赋能业务的覆盖面。其次是从业务规划想法产生到AI算法原型产出,再到AI模型的最终上线,整体流程时间比较长,跟不上企业内部业务创新发展的速度。
第三个挑战是AI算力层面。针对安全服务SaaS化趋势,算法工程师基于机器学习平台有海量的安全数据可以消费使用,如果提供分布式CPU和GPU算力管理能力,可以支撑分布式AI建模;针对新业务或者小规模实验场景,现在主流基于整张物理卡分配或者GRID vGPU方式静态分配都无法实现资源的动态共享,使得高昂贵的GPU算力利用率十分低。
数算工程一体机器学习平台设计方案
基于敏捷开发理念,通过DevOps、DataOps、ModelOps、ServiceOps四个行动,来实现算法开发流程可自动化、AI实验可重现以及AI模型可迭代。当前机器学习平台的重点是实现异构数据的统一治理、异构计算任务的统一调度、多样用户的统一赋能。

异构数据的统一治理是指结构化数据和非结构化基于统一的对象存储服务和统一的元数据管理服务。
异构计算任务的统一调度是指对数据分析型的特征提取任务和AI模型训练任务,针对这两个异构任务,实现一个任务调度和集群管理方案,同时实现异构计算框架之间的数据高效交换。
多样用户统一赋能是指针对专业的算法工程师和业务人员可以统一使用这个机器平台开发AI能力。
深信服的机器学习平台共计分为五个抽象层:

最底层是基础平台层。基于公司的托管云和EDS服务,实现异构AI算力管理,高性能存储以及网络资源的统一调度和管理。
基础平台层上面是数据层。数据层实现海量的结构化、非结构化数据的统一接入和存储服务以及这两类异构数据的元数据的统一管理,同时还实现中间研发数据管理。此外,还提供了基于元数据的数据集数据目录管理功能,方便工程师通过数据schema字段、安全产品类型(AF、SIP、EDR等)、日志类型(http、dns等)、用户名等多维度实现AI研发数据的搜索、详情查看服务。
数据层上面是框架层。包括机器学习或大数据的一些典型计算&训练框架。再往上层是核心计算层,支持自动化机器学习、分布式训练、一键部署,灰度发布等等的机制,以及通过AI Flow进行模型的二次的开发、低代码开发等。
在框架层上面,会持续去沉淀出一些典型场景或者业务中能够更广泛使用的算法能力,最终实现AI能力的二次开发复用,比如说,网络安全领域的网页篡改、病毒检测分析等。
接下来介绍AI研发数据治理模块:
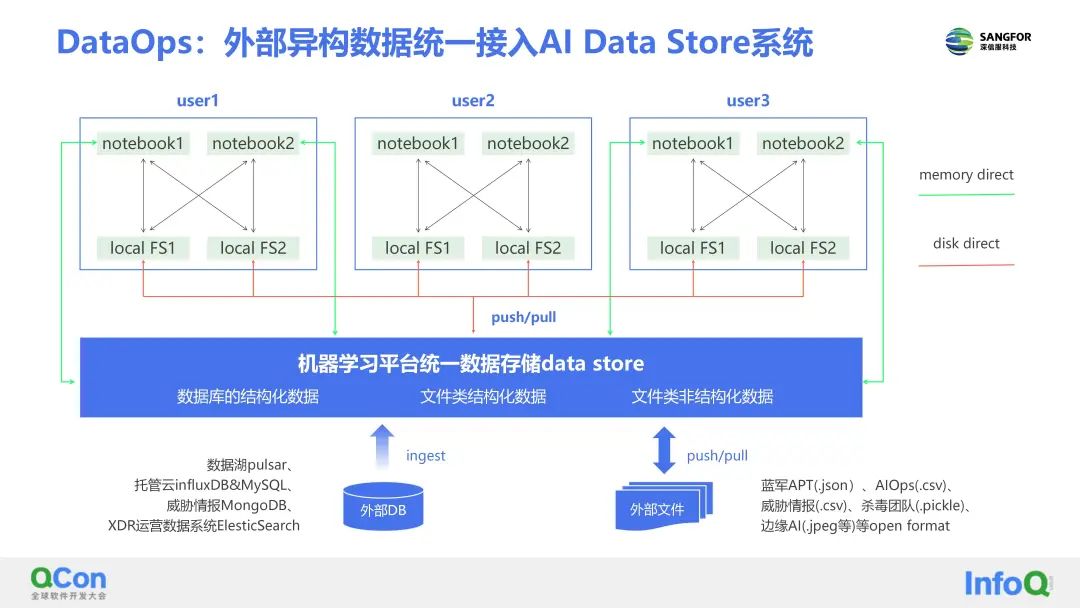
针对外部异构的数据,深信服提出了AI Data Store,一种继承湖仓一体设计理念的多样性AI研发数据统一存储和消费的数据系统,实现了外部数据的统一接入和存储管理。比如数据库类的结构化数据、文件类的结构数据以及文件类的非结构化数据这三类数据,可以统一存储管理。
深信服开发了data store SDK工具或CLI命令行工具,基于CLI命令行,算法工程师就可以像提交代码一样或者代码管理的方式一样去管理自己的数据集,包括支持以push或pull的方式管理AI数据集。
同时也支持向海量的数据操作,即直接内存的方式读取分布式到计算节点,这种方式是可以避免通过notebook本地存储空间的限制,这样会更方便进行大数据或者分布式的计算。

对于data store的实现来说,深信服采用数据抽象分层的设计方案,主要分为三层。
第一层也就是最底层的原始数据层Raw Data Layer, 负责对海量的接入或上传的文件数据进行统一存储管理,算法工程师基于这一层原始数据进行数据清洗以及做一些精细化的特征提取。
提取后的数据存放在Feature Data Layer,这一层的数据还可以进一步转换成用于训练的机器学习训练。
在离线AI算法训练的过程当中,就可以消费ML DataSet Layer的数据,实际上每一层的数据都可以被AI框架直接加载消费。
除了上面的离线消费场景,还有在线消费场景。可以直接从Feature Data Layer这一层实现在线消费。同时,会在Raw Data Layer加一个Slidding Window ,支持Latest-K方式的热数据消费使用,在线消费或者模型灰度测试的时候,可以实现这种相对最新数据的接入,来实现算法的效果验证。
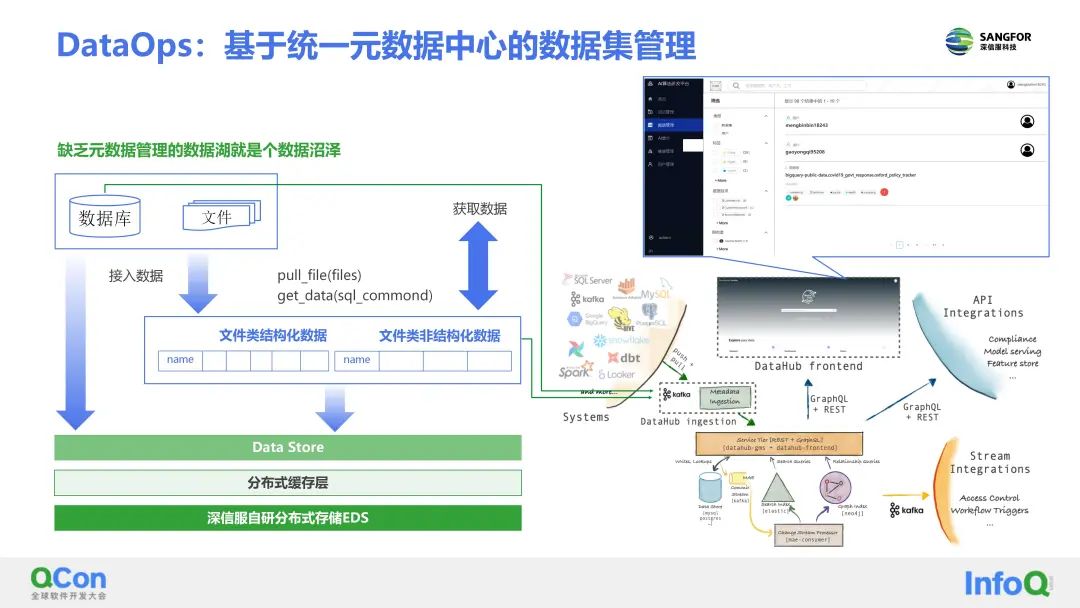
此外,还会通过统一元数据的管理来实现AI数据集CRUD操作。缺少元数据管理的数据湖,本质就是一个数据沼泽,算法工程师或者AI研发人员没有办法高效使用海量数据,即使有海量的业务数据也难以高效率的价值变现。
针对结构化数据和非结构化数据,机器学习平台设计了一个统一的元数据层,支持用户自定义数据集的元数据,由其对于非结构化数据集的管理带来很大的方便,因为非结构化数据本身缺少丰富的元数据,自然也就无法供算法工程师高效和灵活地对文件数据进行CRUD操作。

针对多样性AI任务导致异构计算引擎调度管理难的问题,深信服AI研发团队把AI计算引擎分为两大类,一类是大数据分析型的,主要用于数据清洗、特征提取,比如Spark,Flink;另一类是AI算法计算型的,主要用于ML&DL算法训练,甚至包括图分析、计算框架dgl、graphscope、以及强化学习menger等。
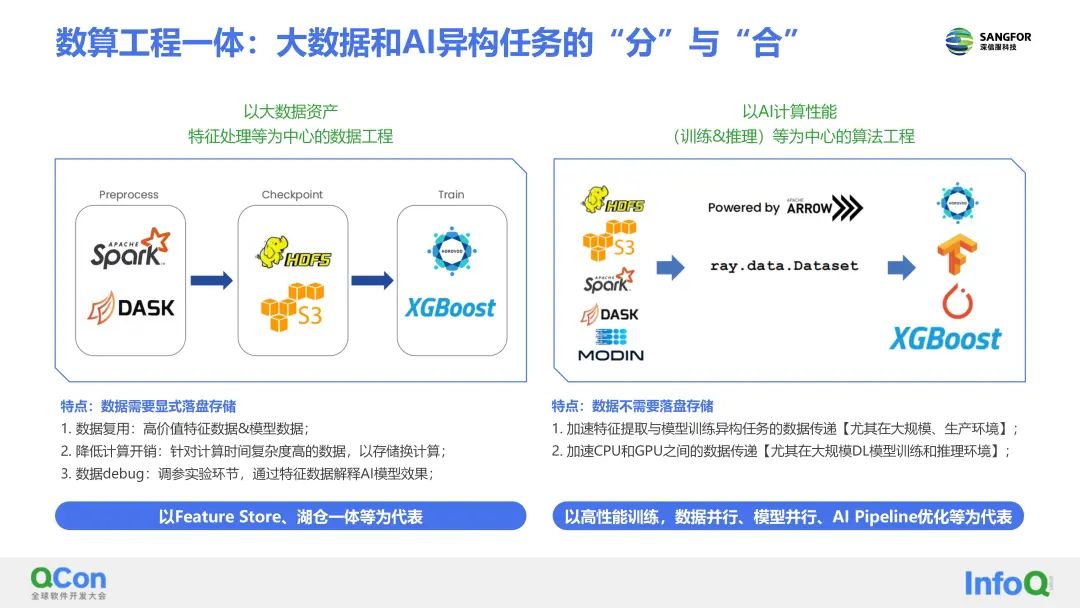
此外,深信服AI研发平台实现了异构计算框架的统一调度和数据的高效通信。
在泛AI领域,大数据分析平台和AI计算平台一直存在两种对接方式:
一种是以大数据资产或特征处理等为中心的数据工程为主,其特点是:数据需要显式落盘存储,以此来实现数据复用、降低计算开销、数据debug。
一种是以以AI计算性能(训练和推理)等为中心的算法工程为主,其特点是:数据不需要落盘存储,以此来实现加速特征提取与模型训练异构任务的数据传递(尤其在大规模、生产环境)、加速CPU和GPU之间的数据传递(尤其在大规模DL模型训练和推理环境)。
这两种异构任务的“分”与“合”,在不同的场景,有其存在的必要性,而深信服机器学习平台建设的目标就是基于一套任务调度框架,实现大数据分析任务和AI计算任务的统一管理。
深信服的解决方式是基于Ray实现异构数据分析和AI计算框架统一调度,避免多套调度引擎,同时基于ML DataSet可以实现框架之间的数据高效传输,有效解决异构分布式任务对接问题。
针对GPU训练数据,深信服通过对dataloader 层面的优化,降低GPU训练任务本身的忙等时间,端到端实现GPU训练任务的优化和加速。具体来说该平台通过两个维度来优化:
维度一:缩短分布式存储系统与分布式计算系统之前的数据传输时间;由于机器学习平台是典型的计算和存储分离架构, 导致AI研发数据访问时延问题,业界做法是在开始模型训练之前:将训练数据复制到本地的磁盘存储中,如普通机械硬盘或者 NVMe、SSD等高速存储设备;将数据提前复制到部署在计算节点上的分布式存储系统中,如Ceph、GlusterFS。
这种额外的AI训练数据迁移过程会面临如下问题:
(1)把训练数据复制到AI计算节点的方式低效且难以管理。手动复制容易出错。像基于notebook的Local FS的方式提供本地计算的手动数据拉去就更加会出现此类数据迁移管理问题;
(2)深度学习训练数量很大且可能持续增加,分布式AI计算节点配置的磁盘容量有限,极容易出现无法存放全量训练数据的情况;
(3)将训练数据存放在多个GPU计算节点上的分布式存储系统内,可以解决数据容量问题,但分布式存储系统自身的运维成本和难度都很大;并且存储系统与计算节点耦合,本身也会产生计算、网络、I/O 等本地资源的争抢和干扰问题。

维度二:基于GPU加速和数据pipeline并行优化数据集预处理的时间;像计算机视觉类任务(钓鱼网页检测、桌面云视频帧超分优化、数据防泄密检测、边缘AI视频分析等)的算法训练会涉及大规模数据集的读取,这些任务都会存在数据集加载效率低导致GPU任务忙等,使得GPU利用率低问题。原生的pytorch&tensorflow框架的data loader是基于CPU实现数据的加载和数据的预处理,这势必会占用worker节点CPU大量的资源。然后将预处理之后的数据从CPU内存交换到GPU显存, 这也会增加IO的开销,降低端到端训练工作流的整体效率。

由于CV类任务的大量操作,比如Resize、Crop、Normlize等都非常适合GPU并行加速,所以深信服选择利用DALI将预处理任务迁移到GPU计算,这样既降低了CPU负载,又提高了GPU的利用率。
针对AI训练任务而言,还有一个特点是数据并非一次性加载到内存或显存,而是以batch迭代的方式加载,这里面就存在CPU 负责加载数据和GPU并行计算两个任务交叉进行的任务。由于这两个子任务的服务和计算特点差异很大,而如果仅以串行的方式执行这两个任务,势必会有一个任务大概率会出现负载相对低的现象。
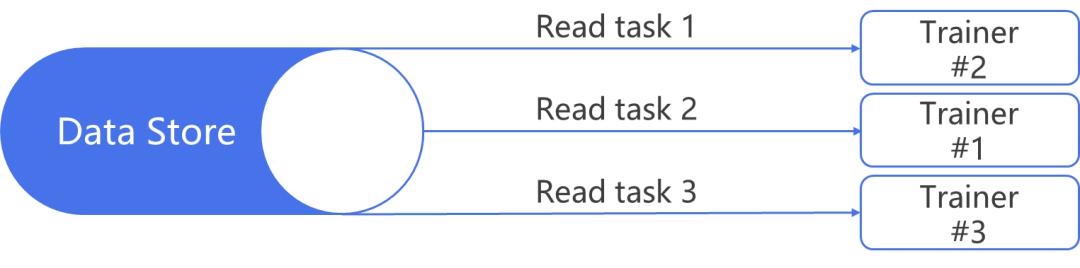
通过将这两个子任务流水线化,可以实现两个子任务执行时间的重叠,最终数据加载和算法训练都可以高负载执行,从端到端加速AI训练速度。

赋能AI研发实践效果
借助于低代码开发算法平台,可以使得各个角色之间高效协作。针对端到端的AI研发人员来讲,如果是任务比较小,算法工程师可以独自完成这些工作。但当AI的任务业务变得比较大的时候,数据特征的提取、模型的调参、算法的测试,包括集成到产品线、产品当中去,就可以利用该平台,实现多角色任务协作。
在数据规模层面,已经实现支持TB级的异构数据的统一管理。在集群规模上,支持10+CPU节点。在研发效率上,大规模病毒文件特征提取时间由45天缩短到15天。

孟宾宾认为,AI的价值落地是围绕实际业务数据、产品系统架构而深度结合和持续优化的AI系统工程。为了产品高性价比,企业需要结合AI硬件做深度的算法、软件、硬件协同优化;为了产品实时性体验,企业甚至要牺牲AI算法一定精度,以减小延迟或提高并发;为了维持产品效果,企业要设计复杂的AI闭环系统,通过ML-Ops实现算法的快速迭代。
以下几点是围绕具体的AI工程化落地,深信服在机器学习平台层面可以探索和持续打磨的方向:
在线(on-line learning)、无监督学习可以降低网络安全标注数据标注门槛、成本。
Al使用门槛可以进一步降低,除了基于AI Flow算法模板和Auto-ML,业界的新兴方案,如可以考虑结余MLSQL进行AI平民化探索。
通过模型漂移、数据漂移检测与持续学习(continue learning),可以持续自动捕捉到安全AI模型的效果漂移问题,持续更新训练模型。
通过数据并行、模型并行、流水线并行的策略进行协同优化基于深度学习和海量数据的复杂模型训练和推理,让业界更复杂、效果更好的AI模型迁移并应用到到公司的网络安全和云计算业务中。
以上就是关于《数算工程一体化机器学习开发平台助力AI算法敏捷开发》的分享,关注“深信服科技”公众号,持续获取更多技术干货内容。














