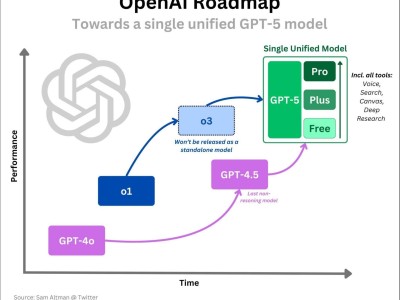
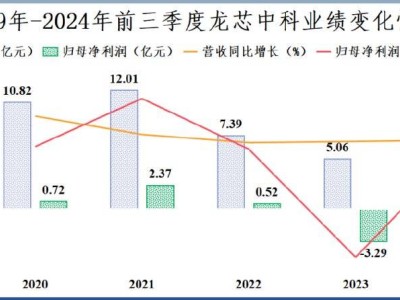
【ITBEAR科技资讯】05月30日消息,自从OpenAI发布了ChatGPT,这一人工智能语言模型在中国科技圈掀起了一场风暴。近半年来,国内约有30家科技大厂、创业公司和机构纷纷宣布推出自己的大模型,但与OpenAI的差距仍然存在。
近期,业界围绕国内大模型与OpenAI之间的差距展开了广泛的讨论。复旦大学MOSS系统负责人邱锡鹏表示,国内包括谷歌在内的模型距离OpenAI的GPT4仍存在很大的差距,不是几个月就能追赶上的。
虽然国内部分企业声称与ChatGPT的差距很小,但邱锡鹏指出,从聊天软件的角度来看,国内大模型与ChatGPT的差别可能不大,但作为生产力工具,两者之间仍然存在代差,追赶这种代差不是几个月就能完成的。

与此同时,国内大模型的算力并不是问题,但核心挑战在于算法和数据能否真正产生智能。网梯科技创始人张震表示,国内可能在一些垂直领域追赶上OpenAI,但在通用领域还需要一段时间。
杨志明是深思考创始人和AI算法科学家,他认为国内大模型与OpenAI之间大约存在1-2代的代差,这涉及整个模型层的技术、学习的知识和能力等方面的差距。杨志明表示,追赶OpenAI的时间不容易衡量,因为不同的速度可能导致追赶时间的差异。
在追赶OpenAI方面,除了算力和技术的挑战外,数据也是一个重要的成本。田丰指出,中文语料库相对于英文来说较少,数据获取和标注的难度较大。此外,构建全球中文数据集需要政产学研多方合作,以加速中文大模型的训练速度与质量。
虽然有一些乐观的声音认为后来者可以在大模型的发展中节省试错成本,但邱锡鹏指出,每家机构的大模型架构都不相同,每一步的细节都是根据研究者的经验和理论推导而来,需要通过试错来不断改进,这仍然是一个成本较高的过程。
在资本方面,国内对于大模型的投资仍然持观望态度。由于大模型领域需要巨额投入、高风险和高回报,目前国内资本还在持币观望状态。然而,邱锡鹏认为,中国能够思考为什么没有造出ChatGPT并且开始追赶,本身就是一种进步。
综上所述,国内的大模型距离OpenAI仍然存在较大的差距。尽管一些企业表示与ChatGPT的差距很小,但作为生产力工具的能力仍然存在代差。追赶OpenAI需要克服算法、数据和资本等多方面的挑战。虽然存在乐观的声音,但在短期内追赶上OpenAI可能性较低。然而,国内的思考和追赶已经是一种进步,展望未来,追赶通用大模型仍然是业界迫切需要解决的问题。