近年来,推荐系统在工业界取得了巨大成功,甚至成为互联网发展中不可或缺的增长引擎,基于此研究者们也在积极探索推荐系统的新形态,其中对话推荐系统(Conversational Recommender System,简称CRS)作为一个备受关注的研究方向被热议。对话推荐系统主要是通过使用自然语言进行多轮对话,逐步了解用户的兴趣偏好,并向他们推荐可能感兴趣的物品。
通常对话推荐主要是以文本形式存在,即用户需要在聊天框内输入文本进行对话,然而在日常生活中,语音作为对话中常见且便捷的承载方式,除语义内容外,还包含性别、年龄、口音、情绪状态等更多信息。经过验证,这些信息可以有效提升对话推荐性能。更重要的一点,基于语音的对话推荐,对于视力障碍以及书写阅读能力有限的人群将会更加友好,因而更加包容。
创新意味着挑战,面对语音对话推荐(Voice-based Conversational Recommender System,简称VCRS)这一全新的研究课题,没有可用的数据集是当下比较棘手的事情。为了解决这个问题,火山语音团队联合新加坡科学研究院团队提出了首个VCRS Benchmark Dataset,论文入选SIGIR 2023,旨在讲述该方面的研究,推动语音对话推荐(Voice-based Conversational Recommender System,简称VCRS)的发展。

论文地址
https://arxiv.org/pdf/2306.08219.pdf
代码链接
https://github.com/hyllll/VCRS
在该数据集生产过程中,双方团队使用了ChatGPT以及语音合成技术,通过在真实推荐数据的基础上模拟生成对应的语音对话推荐数据,并进一步实验验证了语音对话推荐相较于传统的文本对话推荐具有更大优势;基于语音信号,模型可以抽取性别、年龄等辅助信息进一步提升推荐准确率;最后该论文还给出了未来语音对话推荐研究的范式判断,从而激发更多相关工作。

数据集中语音对话推荐过程
VCRS数据集的生产流程
具体来说如下图所示,VCRS数据集的生产过程主要包括四个部分,分别是:
骨干数据集选择(Backbone dataset selection)
文本对话生成(Text-based Conversation Generation)
语音对话合成(Voice-based Conversation Generation)
数据质量评估(Quality evaluation)
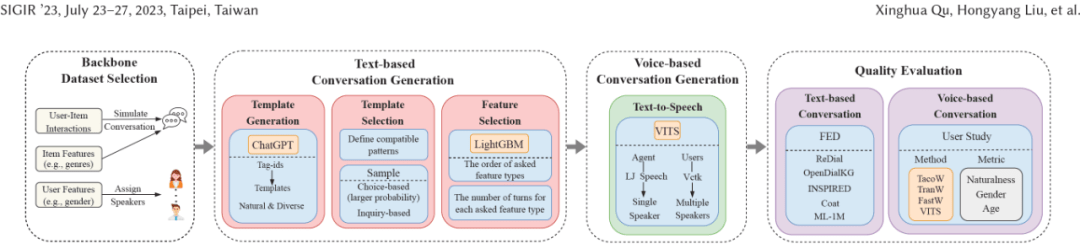
VCRS数据集的生产过程
骨干数据集选择(Backbone Dataset Selection)对于VCRS数据集生产,一个合格的候选骨干数据集需要包含三种信息,分别是用户-商品交互记录、商品特征以及用户特征。通过用户—商品交互记录以及商品特征可以合成文本对话,进而再凭借用户特征(性别、年龄等信息就)就可以完成语音对话合成。根据以上规则,该论文选取了Coat 和MovieLens-1M两个数据集进行了实验。
文本对话生成(Text-based Conversation Generation)论文提出根据对话模板进行slot filling的方式来完成对话语句的生成,该过程主要包含三个部分:
模板生成(Template Generation)
首先需要为每种商品特征(例如衣服颜色、款式等)设计不同形式的询问和回答组合。针对每个组合都分配了一种独特的标签-标识符tag-id,以便在后续的模板选择中方便使用。这种设计有效避免了下图所示“答非所问”的情况,从而使生成的对话更加连贯与紧凑。
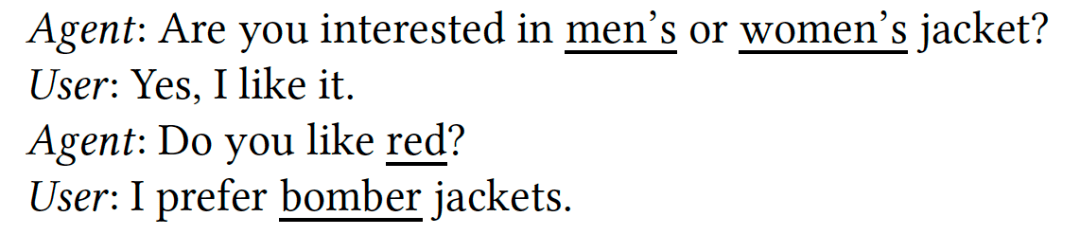
Bad cases: “答非所问”示例
同时该团队还借助于ChatGPT的对话生成能力,在初始模板基础上进行改进和丰富,以增加模板的多样性和自然性;为进一步保证对话的完整性,还在基本的问询/回答模板之外为对话设计了相应的开始/结束模板。
模板选择(Template Selection)
由于在模板生成阶段,每个标签-标识符(tag-id)对应的问答模板已经具有密切相关性,所以在模板选择阶段只需分别从每个标签-标识符下采样问题和答案即可。此外,考虑到很多对话推荐场景下,用户在互动初始阶段通常没有非常清晰的意图,对此团队们采用了有偏的采样策略,即相对于询问类的问题,选择类的问题被赋予更高的采样概率。
特征选择(Feature Selection)
根据上述模板生成和选择的方法,目前可以对某一商品特征进行对话合成,但对于一件商品而言,通常会涉及多个特征,例如颜色与款式等,所以确定不同特征的询问顺序对于推荐结果常常产生显著影响,因此这些特征对用户的偏好具有不同权重。为了解决这个问题,团队们提出了一种利用决策树中的LightGBM方法来计算各个特征权重的方式,具体的计算方法如下图表示:

特征权重计算流程
语音合成(Voice-based Conversation Generation)根据上述文本对话的生成结果,双方团队进一步利用语音合成系统将生成的文本对话转化为相应的语音对话,在此过程中主要采用了当前端到端的VITS系统。对于Agent的语音合成,使用了基于LJSpeech训练的单一说话人TTS模型;而对于User的语音对话合成,则采用了基于VCTK训练的多说话人TTS模型,在该模型中,依据推荐数据集中用户的辅助信息(年龄、性别),与VCTK数据集中的Speaker进行匹配,进而确定User的说话人ID。
数据质量评估(Quality evaluation)为了评估生成的数据质量,团队们分别从文本质量和语音质量两个维度对数据集进行了评估。在文本质量评估过程中使用了目前SOTA的FED (fine-grained evaluation of dialogue)指标,FED使用预训练的DialoGPT模型作为基准来对对话进行18个尺度的评估,具体细则既包含局部评分(如正确性,可读性及流畅性等),又包含了全局评分(如连贯性,一致性及多样性等)。从下述的对比结果中可以看到,合成得到的对话评分超过了人类真实的对话推荐数据集(ReDial, OpenDialKG以及INSPIRED)。
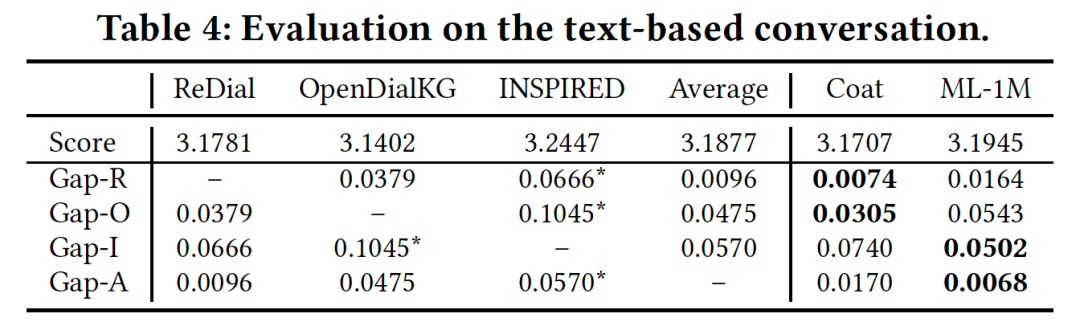
同时下图示例也展示了合成的推荐对话与真实对话相似,并且明显优于之前工作HOOPS中的文本推荐对话。

合成对话示例及对比
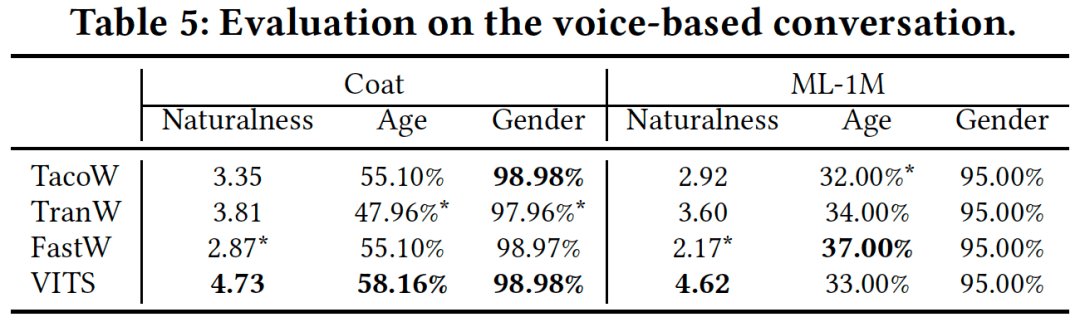
对于语音对话的评估主要采用主观评测的方式,具体做法是将文本对话分别通过多个语音合成系统 (TacoW, TranW, FastW)与VITS进行比较,最终结果如下表所示,VITS明显优于其他模型。
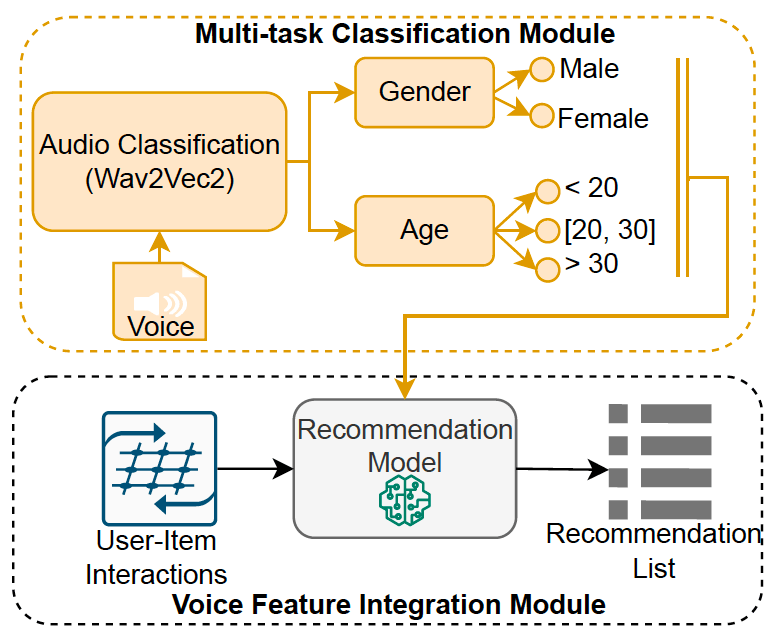
更重要的一点,团队们利用以上合成的VCRS Benchmark Dataset,进一步验证了在推荐性能方面使用该数据集所带来的好处,具体方案如图:
两阶段语音对话推荐解决方案
在推荐模型的训练过程中,语音对话首先经过语音编码器(Wave2Vec2)进行编码,并从中提取出辅助信息(性别、年龄)的表示;随后这些提取到的辅助信息被注入推荐模型中,这一步能够增强推荐模型的性能;此外团队们还给出了未来在语音对话推荐场景下端到端的方案,如下图所示:
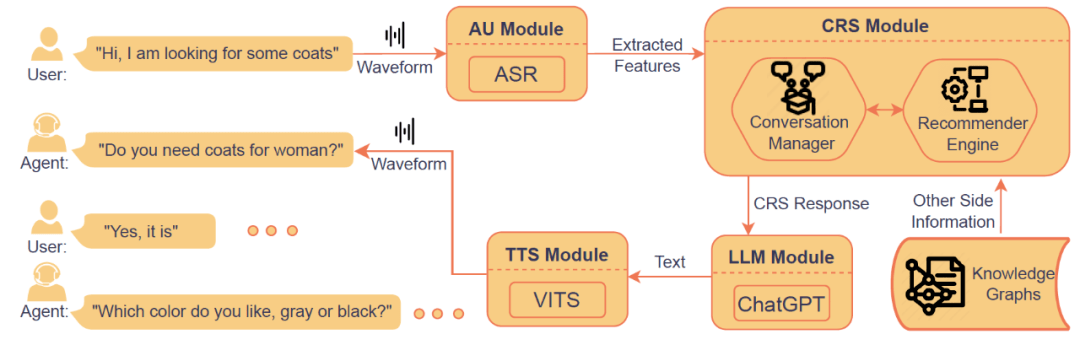
端到端语音对话推荐解决方案
实验结果
论文基于Factorization Machines (FM)在合成的语音对话推荐数据集进行了推荐性能的分析,具体结果所示:
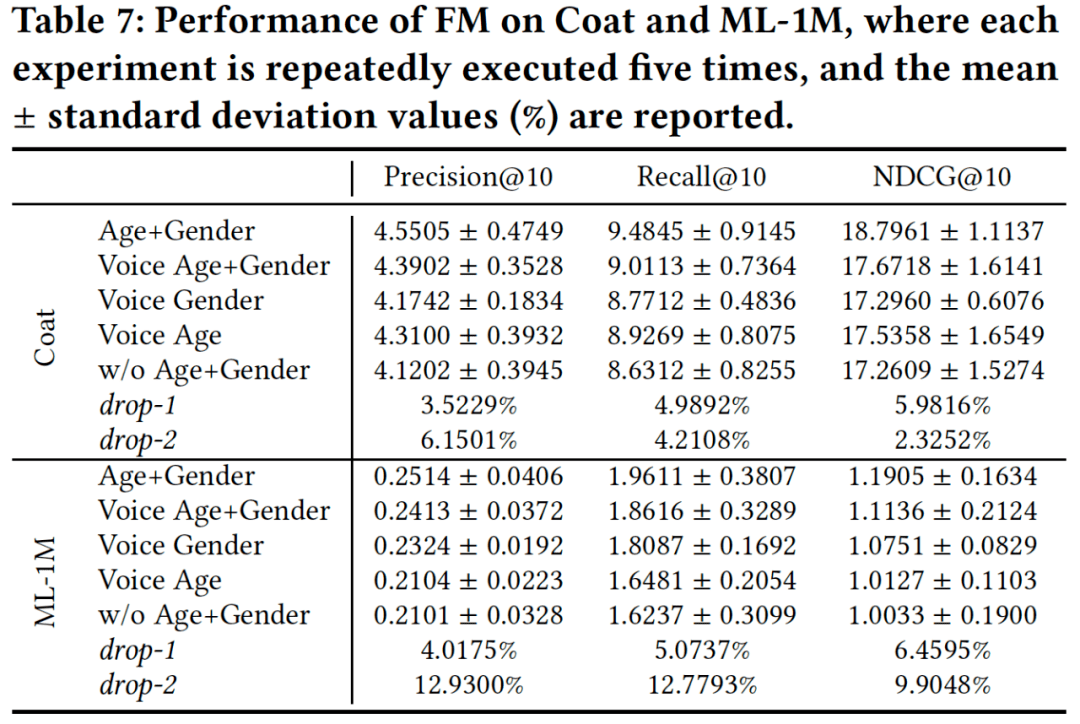
通过实验结果的观察,可以明显看出当语音中融入性别或年龄单一信息时,推荐模型的性能会显著提高;而当性别和年龄信息同时被引入时,模型的性能则进一步得到提升。这一系列实验结果表明,语音对话推荐研究的必要性以及重要性,甚至对于未来在端到端语音推荐场景下所能发现的更多信息充满了信心,在这个领域将会展现出更多令人振奋的发现。
一直以来,火山语音团队面向字节跳动内部各业务线,提供优质的语音AI技术能力以及全栈语音产品解决方案,并通过火山引擎对外提供服务。自 2017 年成立以来,团队专注研发行业领先的 AI 智能语音技术,不断探索AI 与业务场景的高效结合,以实现更大的用户价值。