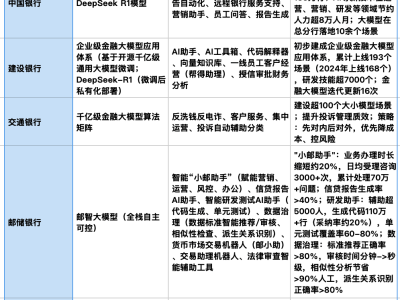
【ITBEAR科技资讯】4月12日消息,近日,百度公司创始人李彦宏在内部讲话中阐述了百度决定不对其人工智能模型文心一言进行开源的原因。在目前国内推出开源模型的公司并不多的情况下,百度的这一决策引起了业界的广泛关注。

李彦宏解释了百度选择不开源模型的几个主要原因。他提到在去年文心一言发布时,百度就预见到市场上将会有多家公司开源其模型。在这种情况下,他认为多百度一家开源并不多,少百度一家也不少。其次,从经济角度出发,对外开源需要维护一套开源版本,这在李彦宏看来并不划算。更重要的是,他坚信闭源模型在能力上会保持持续领先,而非一时之优。
据ITBEAR科技资讯了解,李彦宏还指出,模型开源的实际意义可能并不如预期。他认为,当前的开源模型大多是进行小规模的验证应用,缺乏大规模算力的检验。这与传统的软件开源,如Linux和Android,存在显著差异。他举例说,尽管meta的Llama项目鼓励大家贡献数据和代码,但实际上主要的开发者仍然是meta的团队,Llama并非一个真正由社区协作开发的产品。
李彦宏进一步强调,闭源模型具有真正的商业模式并能创造收益,从而能够聚集更多的算力和人才。此外,在成本方面,闭源模型也具有明显优势。在相同能力下,闭源模型的推理成本更低、响应更快;在相同参数情况下,闭源模型的能力也更强。他还指出,无论在中国还是美国,最强的基础模型都是闭源的,而各种小模型都是通过大模型蒸馏而来,这使得闭源模型在成本和效率上具有优势。
在讲话中,李彦宏似乎暗示百度已经将文心一言视为国内最强的模型,与美国的GPT相提并论。同时,他也对文心一言能够在短时间内快速训练出来的原因保持神秘。这一表态无疑增加了外界对百度人工智能技术的关注和期待。