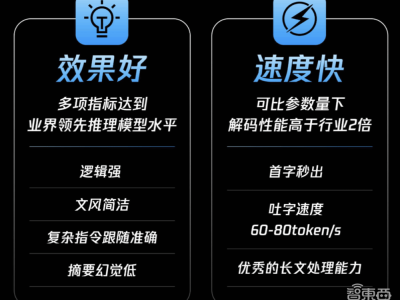
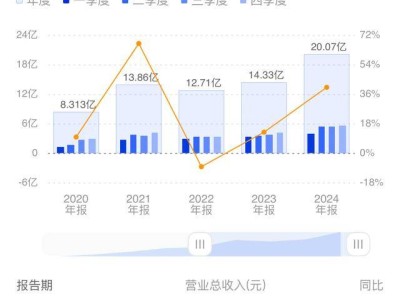
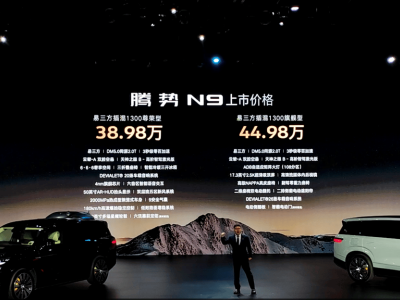
【ITBEAR】9月25日消息,近日,亚利桑那州立大学的科研团队利用PlanBench基准对OpenAI的o1模型进行了规划能力的测试。测试结果显示,尽管o1模型在某些方面取得了显著的进步,但其仍然存在较大的局限性。
PlanBench基准于2022年开发,主要用于评估人工智能系统在规划方面的能力。该基准包含了600个来自Blocksworld领域的任务,要求积木必须按照特定的顺序进行堆叠。
据ITBEAR了解,在Blocksworld任务中,OpenAI的o1模型展现出了惊人的表现,其准确率高达97.8%,远远超过了之前的最佳语言模型LLaMA 3.1 405B的62.6%。在更具挑战性的“Mystery Blocksworld”加密版本中,传统模型几乎全部失败,而o1模型的准确率仍能达到52.8%。
为了验证o1模型的性能是否源于其训练集中的基准数据,研究人员还测试了一种新的随机变体。在这次测试中,o1模型的准确率降至37.3%,但仍远超其他得分接近零的模型。
然而,随着任务的复杂性增加,o1模型的表现也急剧下降。在需要20到40个规划步骤的问题上,o1模型在较简单测试中的准确率从97.8%骤降至23.63%。此外,该模型在识别无法解决的任务方面也显得力不从心,只有27%的时间能够正确识别,而在54%的情况下,它错误地生成了完整但不可能完成的计划。
尽管o1模型在基准性能上实现了显著的改进,但它并不能保证解决方案的正确性。与经典的规划算法相比,如快速向下算法,这些算法可以在更短的计算时间内实现完美的准确性。
研究还指出,o1模型的高资源消耗是一个不容忽视的问题。运行这些测试需要花费近1900美元,而经典算法在标准计算机上运行则几乎不需要任何成本。
研究人员强调,对人工智能系统进行公平比较时,必须综合考虑准确性、效率、成本和可靠性。他们的研究结果表明,尽管像o1这样的人工智能模型在复杂推理任务方面取得了进步,但这些能力仍然有待提升。
关键词:#OpenAI o1模型# #规划能力测试# #PlanBench基准# #局限性# #资源消耗#