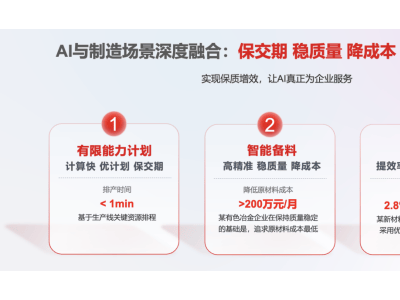
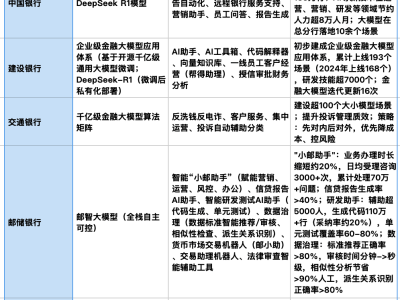
【ITBEAR】近日,Ziff Davis公司公布了一项新研究,揭示了谷歌、OpenAI及meta等AI行业领军企业在训练大型语言模型时,对知名新闻源内容的高度依赖。

该研究深入探讨了AI训练数据集的构成,发现这些数据集主要由新闻和媒体网站的高质量内容组成。这表明,在人工智能技术的发展过程中,主流AI企业已将新闻内容视为训练模型的关键要素。
据悉,Ziff Davis的首席AI律师George Wukoson和技术官Joey Fortuna主导了这项研究。他们详细检查了多个AI公司公开承认使用的数据集,包括Common Crawl、C4、OpenWebText及OpenWebText2。
这一发现不仅揭示了新闻媒体内容在AI训练中的核心价值,同时也引发了关于内容版权和付费问题的讨论。Ziff Davis指出,新闻媒体内容被AI公司无偿使用,这可能导致出版商失去重要的许可收入。
此前,已有出版商对OpenAI提起诉讼,称其未经许可使用内容训练模型。尽管一联邦法官驳回了Raw Story和AlterNet对OpenAI的诉讼,但《纽约时报》提起的相关案件仍在审理当中。同时,OpenAI也已与多家顶级媒体公司达成了许可协议。