在ChatGPT问世后的第二年,人工智能领域正经历一场新的变革。OpenAI及其国内同行正试图超越现有的技术框架,探索大模型发展的新路径。
随着Scaling Law的局限性逐渐显现,今年9月,OpenAI推出了全新系列模型o1,重新定义了“会思考的大模型”。OpenAI的CEO奥特曼对此信心满满,认为AI的发展不仅没有放缓,反而预示着未来几年内的重大突破。
受到o1发布的启发,国内大模型厂商迅速行动,纷纷效仿并推出了各自的o1类深度思考模型。短短两个多月内,kimi的k0 math、Deepseek的DeepSeek-R1-Lite以及昆仑万维的“天工大模型4.0”o1版相继问世,这些模型都着重强调了大模型的逻辑思考能力。
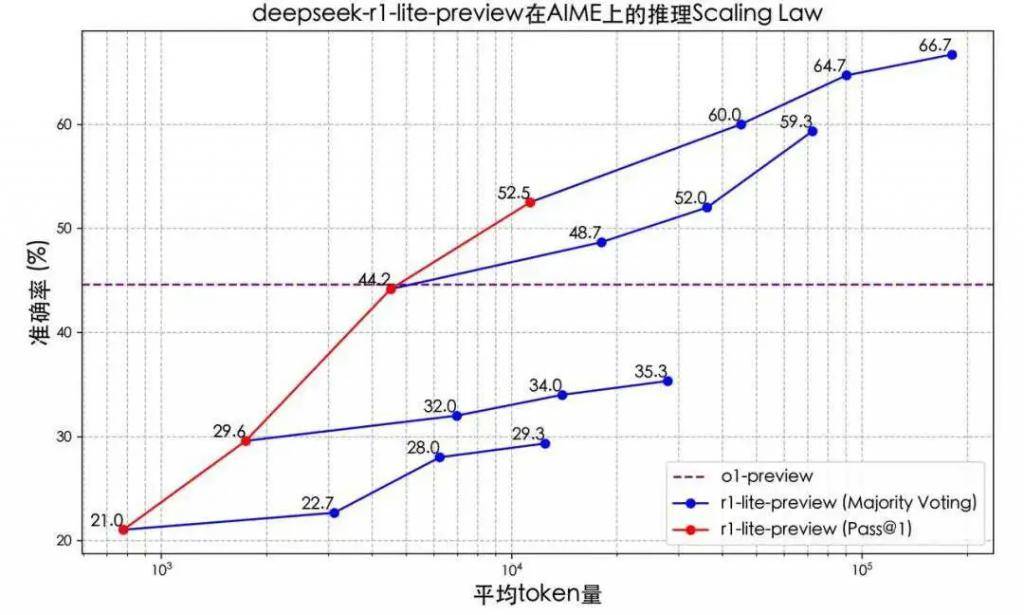
在没有OpenAI公开o1具体技术细节的情况下,国内企业展现出了惊人的研发速度和技术实力。11月16日,月之暗面发布了k0 math,通过强化学习和思维链推理技术,显著提升了数学推理能力。四天后,Deepseek推出了DeepSeek-R1-Lite,毫无保留地展示了模型的完整思考过程,其思维链长度可达数万字,并在多项测试中超越了o1-Preview。
昆仑万维也不甘落后,于11月27日发布了天工大模型4.0 o1版,成为国内首款实现中文逻辑推理的模型。该模型提供了三种版本,包括开源的Skywork O1 Open、优化中文支持能力的Skywork O1 Lite,以及完整展示模型思考过程的Skywork O1 Preview。
这些国产“o1”大模型不仅在数学和代码能力上逼近甚至超过了o1,还学会了“慢思考”。通过引入思维链(CoT),大模型能够将复杂问题拆解为多个小问题,模拟人类的逐步推理过程。这种能力使得大模型在解决一些往常无法回答的问题时,也能给出正确答案。
例如,Deepseek R1在面对“Responsibility中有几个字母i?”的问题时,能够拆解单词并逐一比较字母,最终给出正确答案。昆仑万维的大模型在面对陷阱问题时,也能通过思维链模式自行避开问题,找到准确的翻译结果。
然而,慢思考模型也面临着挑战。虽然它们在一些特定学科上的表现大幅提升,但大量耗费tokens的方式却未必能换来用户需要的回报。在某些情况下,增加思维链的长度可以提高效率,但并不意味着在所有情况下都是最优解。因此,大模型需要学会对问题难度进行判别,从而决定是否采用深度思考模式。
从特定场景下的强化学习应用转向通用模型,在训练算力和成本的平衡上还存在一定难度。目前,国产慢思考大模型的开发主要基于规模较小的基座模型,如Skywork O1 Open基于Llama 3.1 8B的开源模型。这意味着在训练RL阶段,所需的算力可能并不比预训练少。
尽管如此,大厂们仍将o1视为下一个必备项。在OpenAI和智谱给出的“通往AGI五阶段”的定义中,o1的出现标志着大模型能力突破到了L2阶段,开始真正拥有逻辑思维能力。国内厂商在同步跟进o1类产品的同时,已经开始思考如何将o1的能力与现有AI应用方向结合。
在数据枯竭的情况下,o1为Scaling Law提供了新的支撑。更多大模型公司的加入,将联手探索出更大的可能性。同时,思维链的能力已经帮助提升了AI技术的使用效果。例如,智谱的“会反思的AI搜索”结合了思维链能力,能够给出更加精准的答案。

当大模型开始学会“自我思考”,通往L3(Agent)的大门也正在被推开。然而,如何平衡大模型的推理进化和用户对效率的需求,仍然是国内大模型厂商需要解决的问题。