
腾讯在AI视频生成领域迈出了重要一步,正式上线了其混元大模型的视频生成功能。这一功能是在腾讯已经实现的文本生成文本、文本生成图像以及3D生成能力之后的又一技术突破。
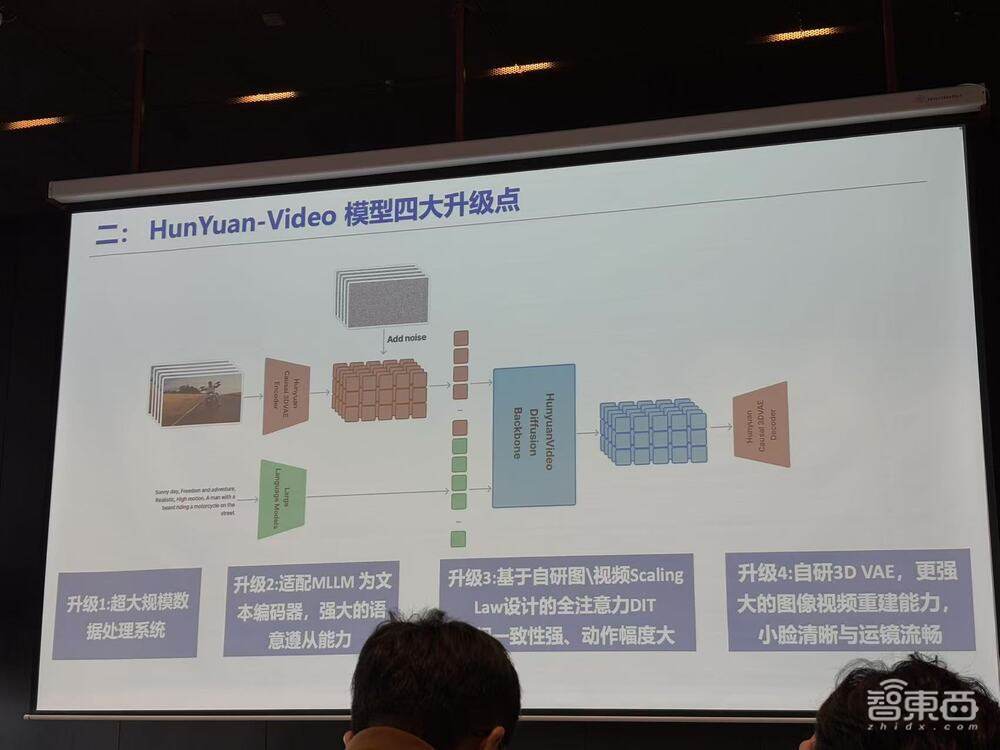
腾讯混元多模态生成技术的负责人凯撒在介绍中表示,此次更新的HunYuan-Video模型经历了四大核心改进。首先,引入了超大规模的数据处理系统,显著提升了视频画质。这一系统能够混合处理图像与视频数据,通过多个维度的功能,如文字检测、转景检测、美学打分等,进一步优化了视频质量。

其次,模型采用了多模态大语言模型(MLLM)作为文本编码器,提升了复杂文本的理解能力,并实现了多语言支持。这一改进使得文本与图像之间的对齐更加精确,能够根据用户提供的提示词生成符合要求的视频内容。
模型架构方面,HunYuan-Video使用了130亿参数的全注意力机制(DIT)和双模态ScalingLaw,有效利用了算力和数据资源,增强了时空建模能力,并优化了视频生成过程中的动态表现。这一架构支持原生转场,实现了多个镜头间的自然切换,同时保持了主体的一致性。

最后,腾讯自研的3D VAE架构被应用于HunYuan-Video模型中,以提升图像和视频重建的能力。这一架构特别在小人脸和大幅运动场景下表现更加流畅,进一步增强了视频的视觉效果。
与此同时,腾讯宣布将这款拥有130亿参数规模的视频生成模型进行开源,并在APP与Web端发布。用户可以在标准模式下大约120秒内完成视频生成。这一举措将极大地促进AI视频生成技术的发展和应用。
在技术升级之外,腾讯还对HunYuan-Video模型进行了多项应用拓展。通过微调、应用拓展及开源等措施,腾讯进一步强化了模型的实际应用能力。目前,HunYuan-Video正在六个关键方面进行专项微调,包括画质优化、高动态效果、艺术镜头、手写文本、转场效果以及连续动作的生成。这些微调将进一步提升模型在视频生成方面的定向能力。

HunYuan-Video还推出了Recaption模型,提供了常规模式和导演模式两种生成模式。常规模式适合专业用户进行精细操作,而导演模式则更适合非专业用户使用,通过提升画面质感、强化镜头运用等方面,帮助用户生成高质量的视频内容。

腾讯混元大模型在视频生成领域的表现也获得了认可。经过千题盲测的定量分析,混元在总体排序中以41.3%的表现领先,优于其他多个模型。特别是在处理人文场景、人工场所以及多主体组合场景时,其生成效果尤为突出。这一成绩显示了腾讯在AI视频生成领域的强大实力。



















