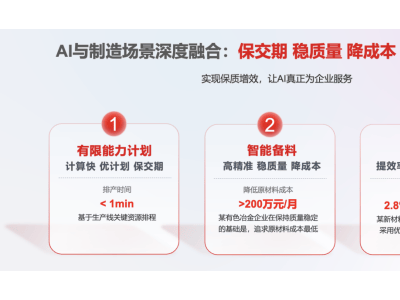
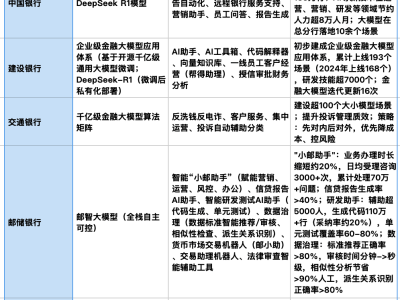
近期,科学界对解码动物交流的研究表现出了前所未有的乐观态度。据 Munich Eye 报道,2025年,人工智能(AI)和机器学习领域的重大突破有望帮助我们揭开动物发声背后的秘密,这一领域的研究正在取得令人瞩目的进展。
为了推动这一领域的研究,Coller-Dolittle 奖项的设立为解码动物声音的研究团队提供了丰厚的奖金支持。这一举措不仅彰显了科学界对动物交流研究的重视,也激发了更多研究人员的热情和动力。

当前,多个研究项目正在积极开发能够解读动物声音的算法。其中,Ceti 计划尤为引人注目。该计划致力于破解抹香鲸独特的点击声和座头鲸悠扬的歌声,然而,高质量的动物声音数据稀缺一直是制约研究进展的关键因素。相比之下,大型语言模型如ChatGPT能够利用互联网上的海量文本数据进行训练,而动物交流研究的数据集却显得捉襟见肘。
例如,Ceti 计划在研究抹香鲸声音时,所获得的录音样本数量不足8000个,这与LLMs训练所需的超过500GB的文本数据量形成了鲜明对比。这一数据差距不仅凸显了动物交流研究的难度,也促使研究人员不断探索新的方法和途径来收集和分析数据。
解读动物叫声还面临着诸多不确定性。与人类语言不同,动物叫声缺乏共同的语法和语义规则。因此,区分不同狼嚎叫所代表的意义仍然是一个巨大的挑战。然而,随着数据集的逐渐完善,深度神经网络等先进的分析技术将有望揭示动物声音背后的规律和结构。
一些组织如Interspecies.io甚至提出了更为大胆的设想,他们希望将跨物种的交流转化为人类能够理解的信号,甚至将动物的叫声翻译成人类语言。然而,科学界对此持谨慎态度。他们认为,非人类动物并不具备类似人类语言那样的结构化语言,因此将动物叫声翻译成人类语言可能是一个不切实际的目标。
尽管如此,研究人员对解码动物声音的最终目标仍然充满期待。他们相信,随着技术的不断进步和数据的不断积累,我们有望更加深入地理解动物的交流方式,从而更好地保护和研究这些珍贵的生物。