近期,杭州深度求索人工智能基础技术研究有限公司(以下简称“深度求索”)发布了一则令人瞩目的消息,其最新研发的DeepSeek-V3系列模型的首个版本已经正式上线,并且公司已经决定将其开源。这一消息于12月26日正式对外公布。
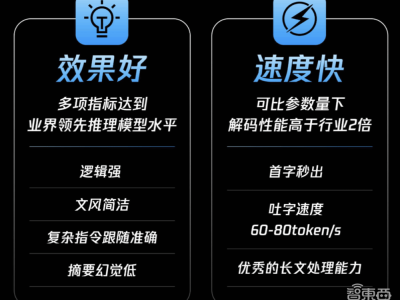
深度求索方面表示,DeepSeek-V3在多项评测中展现出了卓越的性能,超越了Qwen2.5-72B和Llama-3.1-405B等知名的开源模型。更令人瞩目的是,DeepSeek-V3在性能上与世界顶尖的闭源模型,如GPT-4o和Claude-3.5-Sonnet,也达到了相当的水平。这一成就无疑展示了深度求索在人工智能领域的深厚实力。
在官方公布的技术论文中,深度求索透露了v3模型的总训练成本为557.6万美元,相较于GPT-4o等模型的约1亿美元训练成本,显得更为经济高效。这无疑为人工智能领域的研究和开发带来了新的启示,表明高效且成本效益高的模型训练方法正在成为可能。
然而,尽管DeepSeek-V3在性能和成本上取得了显著的成就,但在实际测试中,该模型却出现了一个有趣的小插曲。当被问及它是哪家大模型时,DeepSeek-V3竟给出了“ChatGPT”的答案。这一bug显然有些出乎意料,目前也尚未得到修复。这一现象也引发了人们对人工智能模型准确性和可靠性的进一步思考。

不过,值得注意的是,当使用中文进行提问时,DeepSeek-V3则能够正确地报出自己的身份。这一表现也显示了该模型在中文处理上的优势和能力。这一发现也为未来人工智能模型在跨语言处理方面的发展提供了新的可能性和方向。