在人工智能领域,一场悄无声息的革命正在上演。1月20日,DeepSeek团队震撼发布了其最新开源模型——DeepSeek-R1,该模型一经推出,便在GitHub上迅速收获了超过4000个星标,成为大模型领域的焦点。
DeepSeek-R1的问世,不仅打破了之前关于其是否基于OpenAI o1进行蒸馏的传言,团队更是直接宣称:“我们的模型可以与开源版的o1一较高下。”这一声明无疑为DeepSeek-R1增添了更多神秘色彩。
值得注意的是,DeepSeek-R1在模型训练上实现了重大突破,摒弃了传统的SFT数据,完全依赖于强化学习(RL)进行训练。这一改变意味着模型已经具备了自我思考的能力,更加贴近人类的思维模式。
网友们对DeepSeek-R1的评价颇高,甚至有人将其誉为“开源LLM界的AlphaGo”。这一赞誉不仅体现了DeepSeek-R1的强大实力,也反映了公众对于开源模型发展的期待。
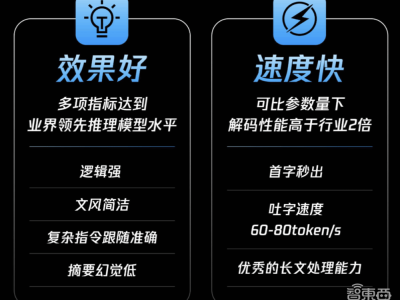
DeepSeek团队的自信并非空穴来风。在后训练阶段,DeepSeek-R1凭借有限的数据,在模型推理能力上远超o1。在数学、代码和自然语言推理等多个领域,DeepSeek-R1都展现出了卓越的性能。

例如,在AIME 2024数学竞赛中,DeepSeek-R1取得了79.8%的成绩,略高于OpenAI的o1-1217。在MATH-500测试中,DeepSeek-R1更是达到了97.3%的高分,与o1-1217相当,同时显著优于其他模型。在编程竞赛方面,DeepSeek-R1也表现出了专家级水平,其Codeforces上的Elo评级达到了2029,超过了96.3%的人类参赛者。

DeepSeek团队还开源了6个参数不同的小模型,包括1.5B、7B、8B、14B、32B和70B。这些蒸馏过的模型在性能上不仅超越了GPT-4o、Claude 3.5 Sonnet和QwQ-32B,甚至与o1-mini的效果相当。
更令人惊叹的是,DeepSeek-R1在成本上仅为o1的五十分之一,却能实现与o1相同的效能。这种高性价比让DeepSeek-R1成为了“花小钱,办大事”的典范。

DeepSeek-R1的成功不仅在于其卓越的性能,更在于其开源的训练数据集和优化工具。这一做法让不少网友直呼:“这才是真正的Open AI。”DeepSeek团队的核心技术包括Self play、Grpo以及Cold start,这些技术的运用使得DeepSeek-R1在训练过程中能够自主思考、自我优化,从而实现了性能上的飞跃。
DeepSeek-R1的发布引起了国内外大模型从业者的广泛关注。深度赋智CEO吴承霖评价道:“DeepSeek R1确实厉害,但方法非常简单,核心其实就三点。”这三点正是Self play、Grpo以及Cold start,它们共同构成了DeepSeek-R1成功的基石。