Hugging Face平台近日宣布了一项重要进展,推出了两款专为算力受限设备设计的轻量级AI模型——SmolVLM-256M-Instruct与SmolVLM-500M-Instruct。这两款模型的发布,标志着在资源有限的环境下,AI技术的应用潜力得到了进一步拓展。
早在2024年末,Hugging Face就曾推出过一款名为SmolVLM的视觉语言模型(VLM),该模型凭借仅20亿参数的高效设计,在设备端推理领域展现出了卓越的性能,尤其是其极低的内存占用,更是成为了同类模型中的佼佼者。
而此次推出的SmolVLM-256M-Instruct,更是将参数规模压缩至了2.56亿,成为了有史以来发布的最小视觉语言模型。这款模型能够在内存低于1GB的PC上流畅运行,为用户提供出色的性能表现。对于资源受限环境下的开发者而言,这无疑是一个巨大的福音。
与此同时,SmolVLM-500M-Instruct也以其5亿参数的规模,展现了强大的数据处理能力。这款模型主要针对硬件资源受限的场景设计,旨在帮助开发者应对大规模数据分析的挑战,实现AI处理效率和可访问性的双重突破。
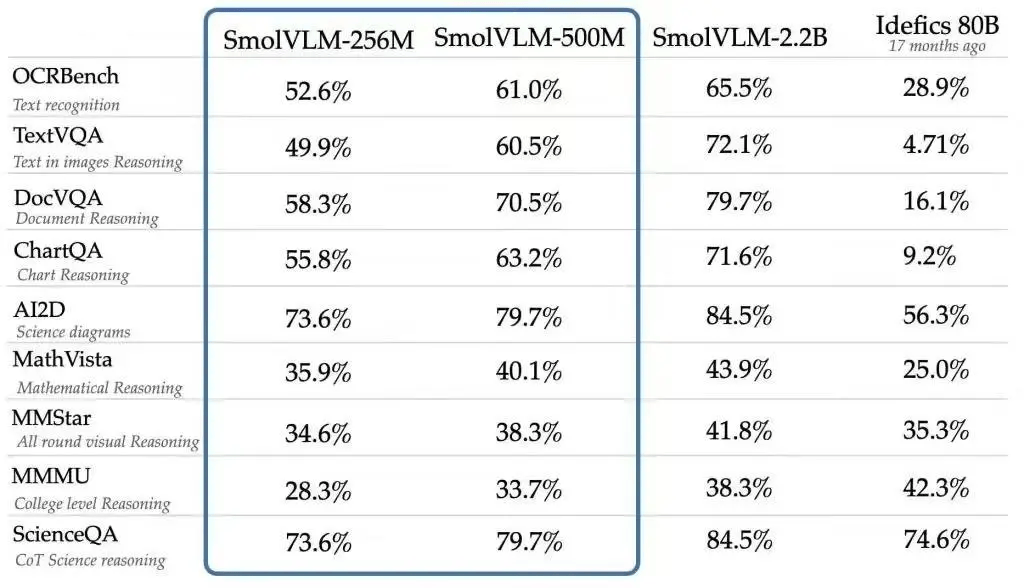
SmolVLM系列模型不仅参数规模小巧,更具备先进的多模态能力。无论是图像描述、短视频分析,还是回答关于PDF或科学图表的问题,这些模型都能游刃有余地完成。Hugging Face表示,SmolVLM在构建可搜索数据库方面,不仅速度更快、成本更低,其性能甚至能与规模十倍于自身的模型相媲美。
为了打造这些高效的AI模型,Hugging Face团队依赖了两个专有数据集:The Cauldron和Docmatix。The Cauldron是一个精选的高质量图像和文本数据集集合,专注于多模态学习;而Docmatix则专为文档理解而设计,通过配对扫描文件与详细标题,增强了模型的理解能力。
在模型架构方面,SmolVLM-256M-Instruct和SmolVLM-500M-Instruct采用了更小的视觉编码器SigLIP base patch-16/512,相较于SmolVLM 2B中使用的SigLIP 400M SO,这一优化减少了冗余,提高了模型处理复杂数据的能力。这两款模型还能够以每个标记4096像素的速率对图像进行编码,相较于早期版本的每标记1820像素,有了显著的性能提升。