百川智能近日正式揭晓了其最新研发成果——Baichuan-Omni-1.5开源全模态模型,这一创新模型现已正式上线。Baichuan-Omni-1.5不仅精通文本、图像、音频和视频的全模态理解,还独具文本与音频的双模态生成能力,展现了强大的多模态处理能力。
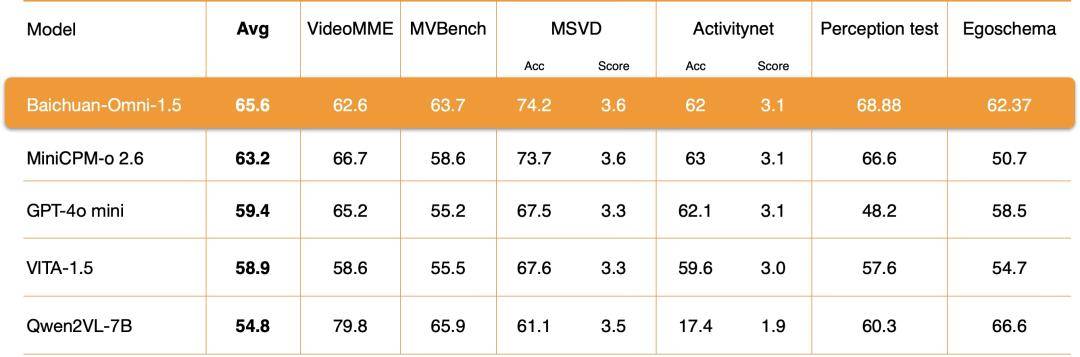
据官方宣称,Baichuan-Omni-1.5在视觉、语音及多模态流式处理等多个领域,其性能均超越了GPT-4o mini。特别是在多模态医疗应用领域,该模型更是展现出显著的领先优势,为医疗智能化发展开辟了新路径。
该模型在交互操作上也实现了重大突破,支持输入与输出端的多样化交互,同时拥有卓越的多模态推理能力和跨模态迁移能力。这一特性使得Baichuan-Omni-1.5能够灵活应对各种复杂场景,实现高效的信息处理与转换。
在音频技术领域,Baichuan-Omni-1.5采用了先进的端到端解决方案,支持多语言对话、端到端音频合成,以及自动语音识别、文本转语音等功能。该模型还支持音视频实时交互,为用户提供了更加流畅、自然的交互体验。
在视频理解能力方面,Baichuan-Omni-1.5通过对编码器、训练数据和训练方法等多个关键环节的深度优化,实现了整体性能的显著提升,远远超越了GPT-4o mini。这一突破性的进展使得Baichuan-Omni-1.5在视频处理领域具有更强的竞争力和应用前景。
在模型结构上,Baichuan-Omni-1.5的设计同样独具匠心。其输入部分支持各种模态数据通过相应的Encoder/Tokenizer输入到大型语言模型中,实现了数据的多样化处理。而在输出部分,该模型则采用了文本-音频交错输出的设计,通过Text Tokenizer和Audio Decoder同时生成文本和音频,实现了信息的多维度输出。
为了构建这一强大的模型,百川智能投入了大量资源,构建了一个包含3.4亿条高质量图片/视频-文本数据和近100万小时音频数据的庞大数据库。在SFT阶段,更是使用了1700万条全模态数据进行训练,确保了模型的准确性和可靠性。
对于广大开发者而言,Baichuan-Omni-1.5的开源无疑是一个重大利好。现在,开发者可以通过以下链接获取模型权重和技术报告,深入了解并应用这一创新模型:
GitHub链接:https://github.com/baichuan-inc/Baichuan-Omni-1.5
模型权重链接:
Baichuan-Omni-1.5:https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5 https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5
Baichuan-Omni-1.5-Base:https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Base https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5-Base
技术报告链接:https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf