在AI技术日新月异的今天,一场由国内新兴AI企业引领的技术风暴正悄然席卷全球。今年的春节假期前夕,一场没有硝烟的战争在AI领域悄然打响,而主角并非传统互联网巨头,而是名不见经传的“大模型公司”DeepSeek。
就在春节前一周,DeepSeek公司震撼发布了其推理模型DeepSeek-R1正式版。这款模型以低廉的训练成本,实现了与OpenAI顶尖推理模型相媲美的性能,并且完全免费开源。此举如同一颗重磅炸弹,瞬间在行业内引发巨大轰动。国产AI技术首次在全球范围内,尤其是在美国科技圈,掀起了一场技术革命。
开发者们对DeepSeek的热情空前高涨,纷纷表示正在考虑用DeepSeek来“重构一切”。在这一波热潮的推动下,DeepSeek于一月刚刚发布的移动端应用,迅速攀升至美区苹果应用商店免费App排行榜首位,不仅超越了ChatGPT,还力压其他热门应用,成为市场焦点。
DeepSeek的成功甚至对美股市场产生了直接影响。其以低成本训练出高性能模型的事实,迫使业界重新审视AI的训练路径,导致AI第一股英伟达股价大幅波动,最大跌幅达到17%。
然而,DeepSeek的征程并未止步。就在除夕夜前一晚,该公司再次宣布开源其多模态模型Janus-Pro-7B,并在Geneval和DPG-Bench基准测试中击败了来自OpenAI的DALL-E 3和Stable Diffusion。这一连串的突破,让DeepSeek成为了全球AI领域的焦点。
Janus-Pro系列模型是DeepSeek在技术创新上的又一力作。该模型采用了创新的架构,对理解(图生文)和生成任务(文生图)的视觉编码进行解耦,提升了模型训练的灵活性,有效解决了单一视觉编码带来的冲突和性能瓶颈。DeepSeek将这一模型命名为Janus(杰纳斯),寓意模型能像古罗马门神一样,用不同的眼睛看待视觉数据,分别编码特征,然后用同一个Transformer处理这些输入信号。
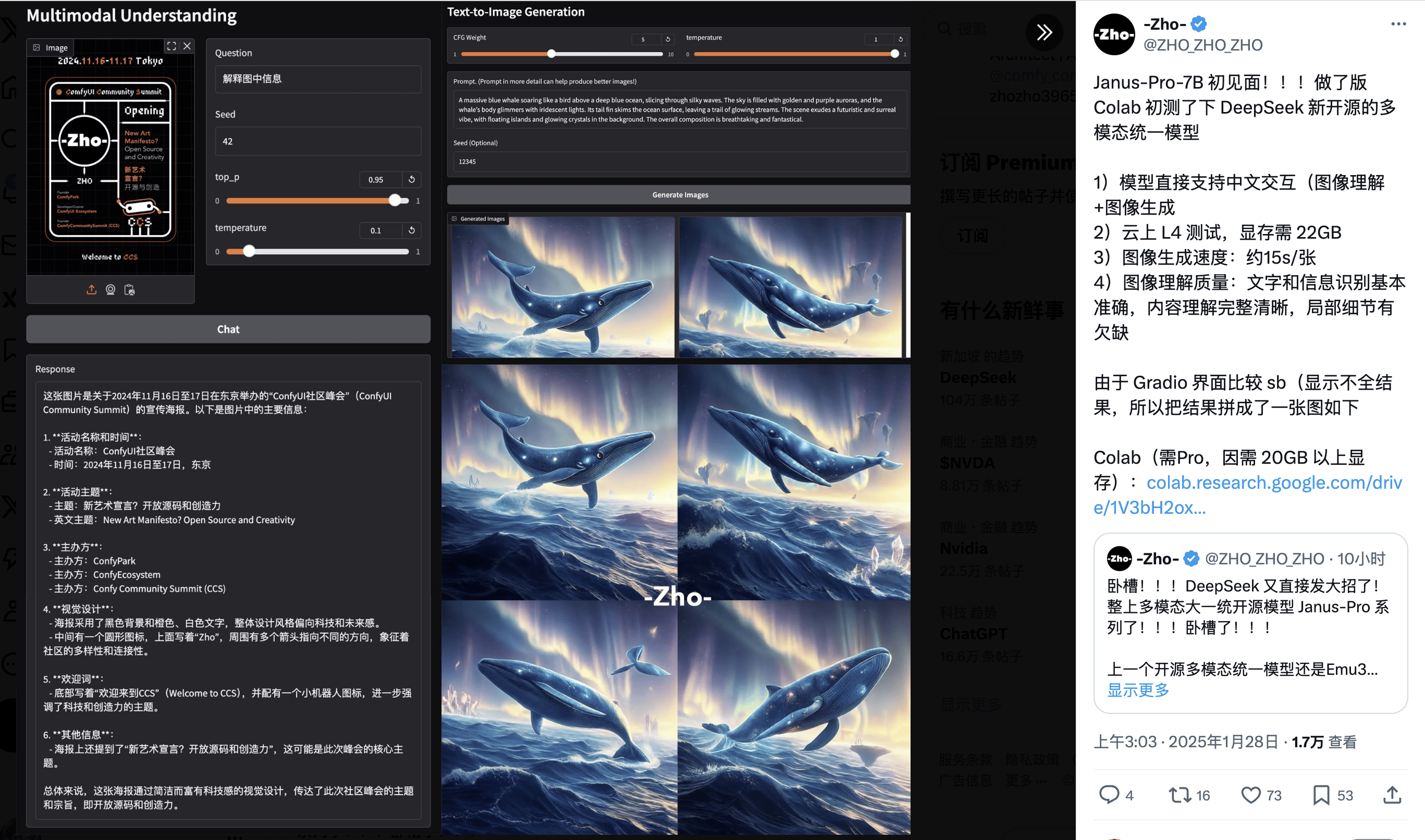
随着Janus-Pro模型的发布,DeepSeek还推出了Janus Flow新型多模态AI框架,旨在统一图像理解与生成任务。Janus-Pro模型能够以简短的提示提供更稳定的输出,具有更好的视觉质量、更丰富的细节以及生成简单文本的能力。它既能生成图像,也能对图片进行描述、识别地标景点、识别图像中的文字,并能对图片中的知识进行介绍。
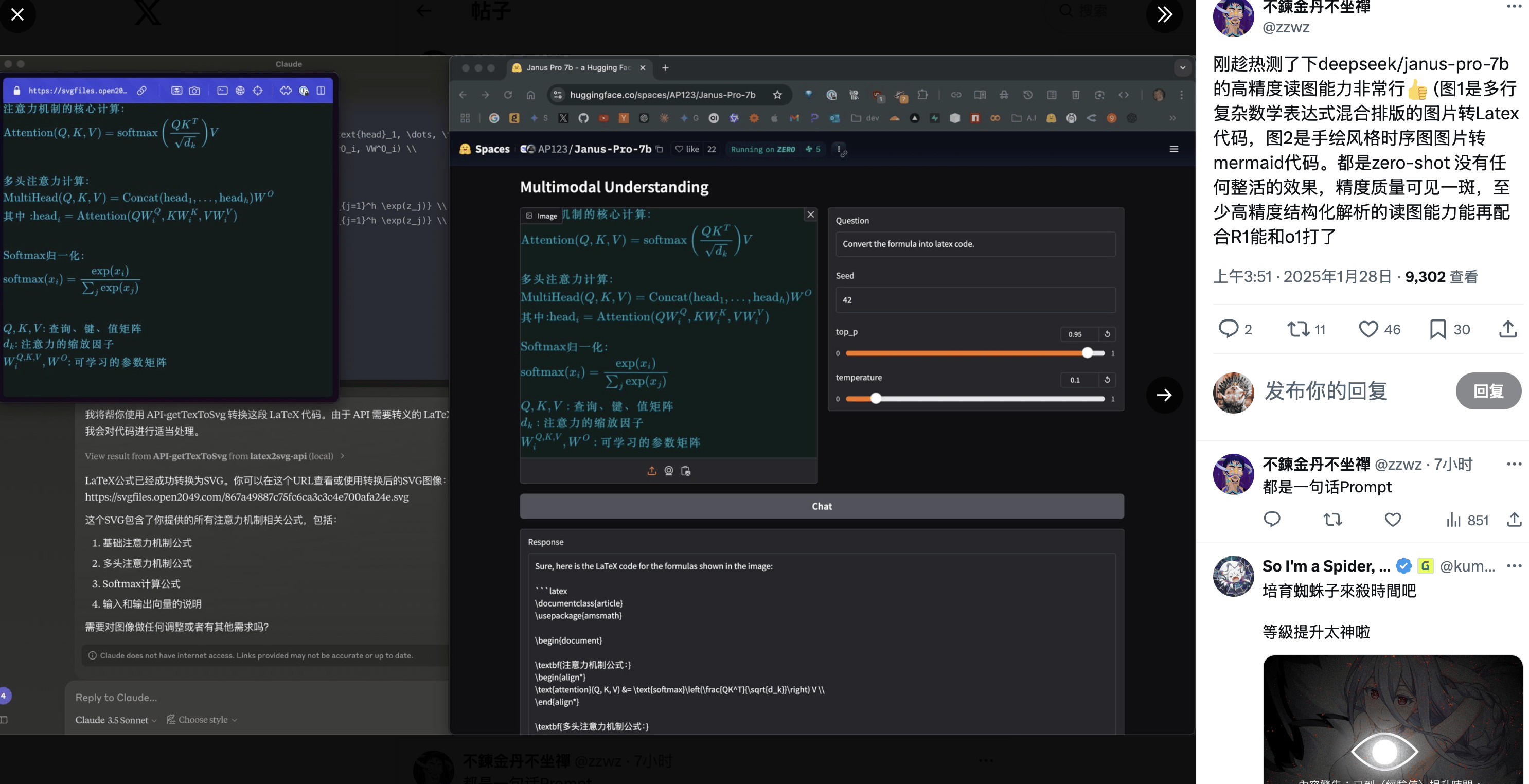
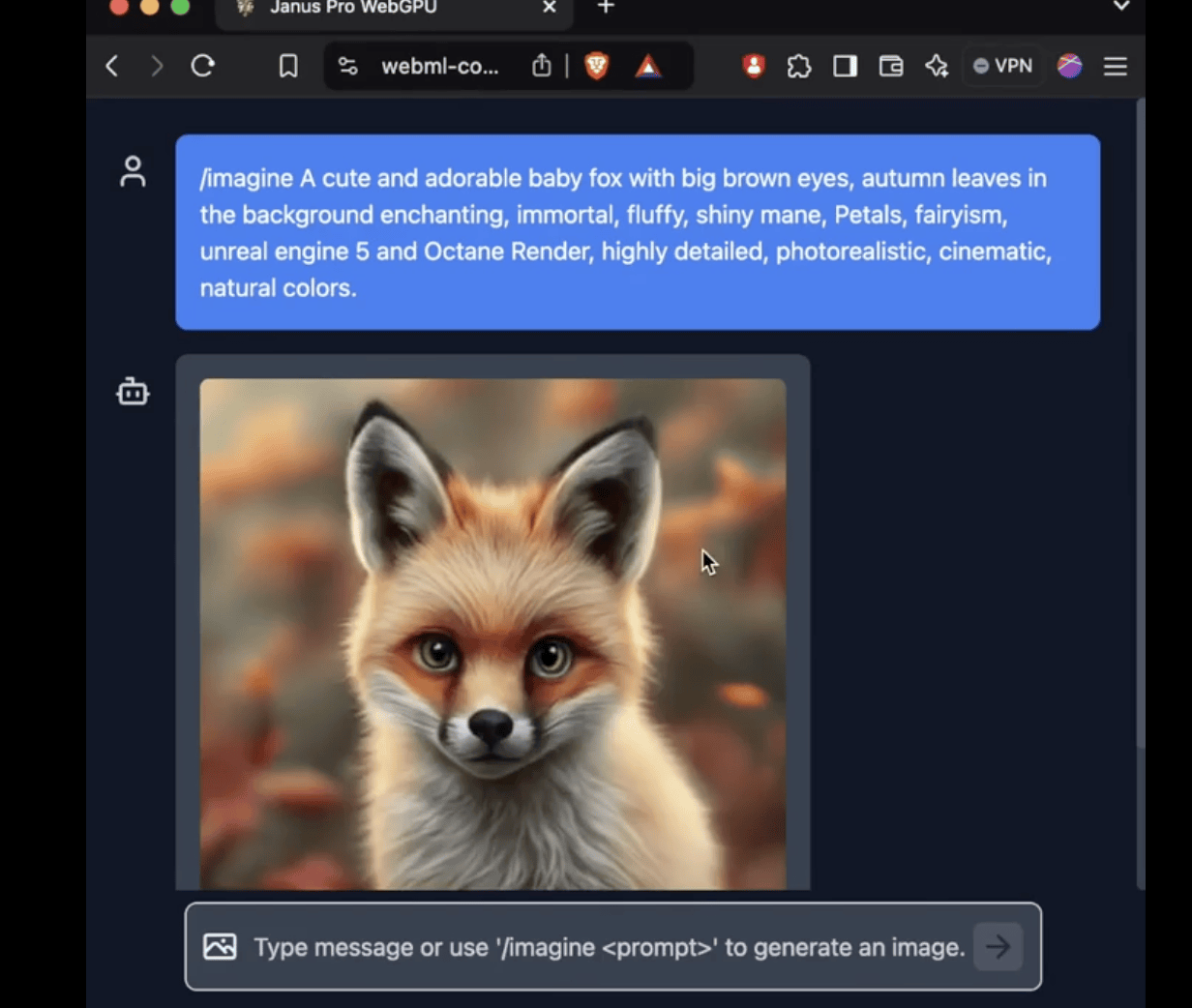
Janus-Pro模型在参数量上的探索也颇具意义。相较于DALL-E 3的120亿参数量,Janus-Pro的大尺寸模型仅有70亿参数,却能在紧凑的尺寸下实现卓越的效果。尤其是其1B模型,仅使用15亿参数,就已能在WebGPU上的浏览器中运行,这一突破意味着图片生成/图片理解的成本正在进一步降低。
DeepSeek的崛起,不仅搅动了国内的AI市场,更在全球范围内引发了广泛关注。其以远低于美国大模型公司的成本,实现了技术创新和性能突破,让美国同行倍感压力。DeepSeek的创始人梁文峰甚至在社交媒体上发布了一张有趣的图片,用土耳其射击选手的梗来暗喻DeepSeek的“以小博大”。
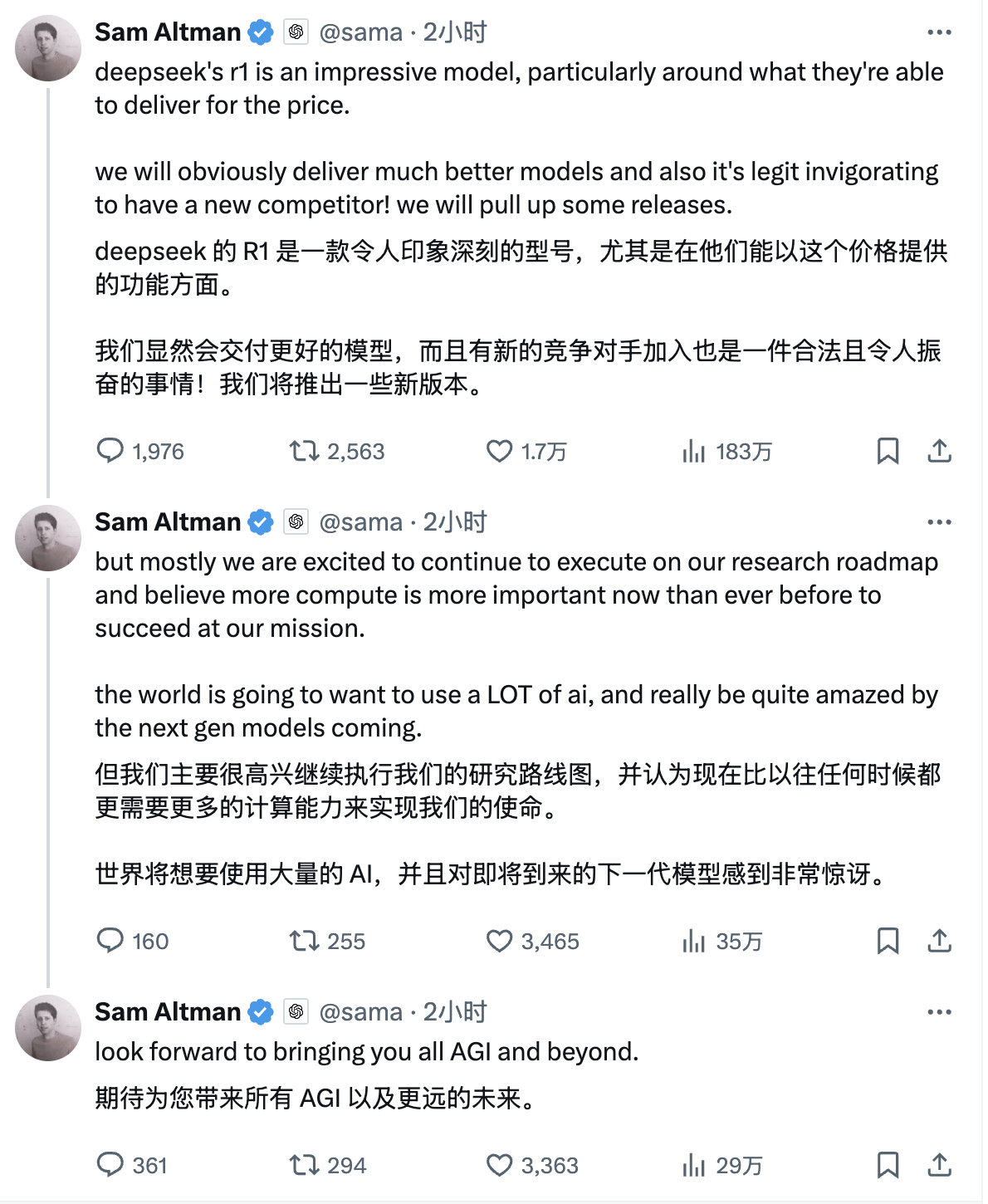
面对DeepSeek的强劲势头,美国科技巨头们也开始坐不住了。OpenAI的CEO Sam Altman也不得不站出来回应这一波来自中国的技术冲击。可以预见的是,2025年将是中国AI技术冲击全球认知的关键一年。
DeepSeek的连续突破,不仅展示了中国在AI领域的强大实力,更为全球AI技术的发展注入了新的活力。未来,随着技术的不断进步和应用场景的不断拓展,DeepSeek有望在全球AI市场中占据更加重要的地位。