在2025年的春节前夕,大模型领域迎来了一场意想不到的“狂欢”。DeepSeek,这家初出茅庐的大模型公司,以一记重拳震撼了整个AI界——它正式开源了DeepSeek-R1,这款模型在数学、代码及自然语言推理等方面,与OpenAI的o1正式版并驾齐驱。
这一消息如同平地惊雷,让众多AI研究者瞠目结舌,纷纷揣测DeepSeek是如何在硬件受限的条件下实现这一壮举的。据悉,DeepSeek采用了一系列技术创新,大幅降低了模型对算力的需求,同时实现了性能的提升。英伟达市值的剧烈波动,更是成为了这场“AI地震”的余波。
DeepSeek的技术创新引发了广泛讨论。许多观点认为,它在算力受限的困境中,走出了一条与OpenAI截然不同的道路。而大洋彼岸的硅谷,对DeepSeek的态度也颇为微妙,从最初的赞誉有加,到后来的网络攻击与审查,这背后折射出的是中国AI崛起的巨大冲击力。
回望过去两年,中国大模型领域的发展犹如脱缰野马,狂飙突进。文心一言、豆包、可灵等国产大模型,已在多个垂直赛道中崭露头角,跨过了曾经看似不可逾越的“护城河”。
以视频生成领域为例,OpenAI在2024年春节期间推出了Sora,被视为视频生成技术的里程碑。然而,仅过了半年,可灵便横空出世,以文生视频技术的实质性领先,让硅谷首次感受到了“中国AI技术的独特优势”。

在语音通话方面,GPT-4o为ChatGPT带来了实时语音通话能力,但用户体验却差强人意。相比之下,豆包实时语音大模型在2025年初正式上线时,其拟人度、有用性、情商、通话稳定性及对话流畅度均令人惊艳。且该功能在豆包App中全面开放,人人皆可免费使用,填补了国产大模型在“端到端语音系统”上的空白。
而DeepSeek-R1的横空出世,更是将这场“AI狂欢”推向了高潮。这款仅用550万美元训练的模型,在短短几周内便从Deepseek-v3基座进化为拥有堪比OpenAI o1的思维链推理能力。其背后的纯强化学习路线及面向H800的大量优化创新,成为了业界热议的焦点。
值得注意的是,推理模型虽是当前最热门的方向之一,但也存在局限性。大模型推理基于当前已知数据,一旦遭遇错误的推理路径,便可能陷入死循环。因此,提升检索增强能力显得尤为重要。而在这方面,文心一言无疑是国内RAG(检索增强生成)能力最领先的大模型应用。
作为国内搜索领域的佼佼者,百度在RAG技术上拥有得天独厚的优势。它基于搜索技术的积累,推出了百度AI原生检索,持续保持领先。从RAG能力实测来看,国内外主流大模型中,百度文心一言的综合表现最为出色。
在实际测试中,文心一言甚至在某些任务上超越了OpenAI的ChatGPT。例如,在回答关于春节档电影细节、春晚节目等内容时,文心一言能够准确回应;而ChatGPT虽能检索到信源,却无法生成准确答案。在回答关于春晚语言类节目、国际新闻等问题时,文心一言同样展现出了更高的准确性和全面性。
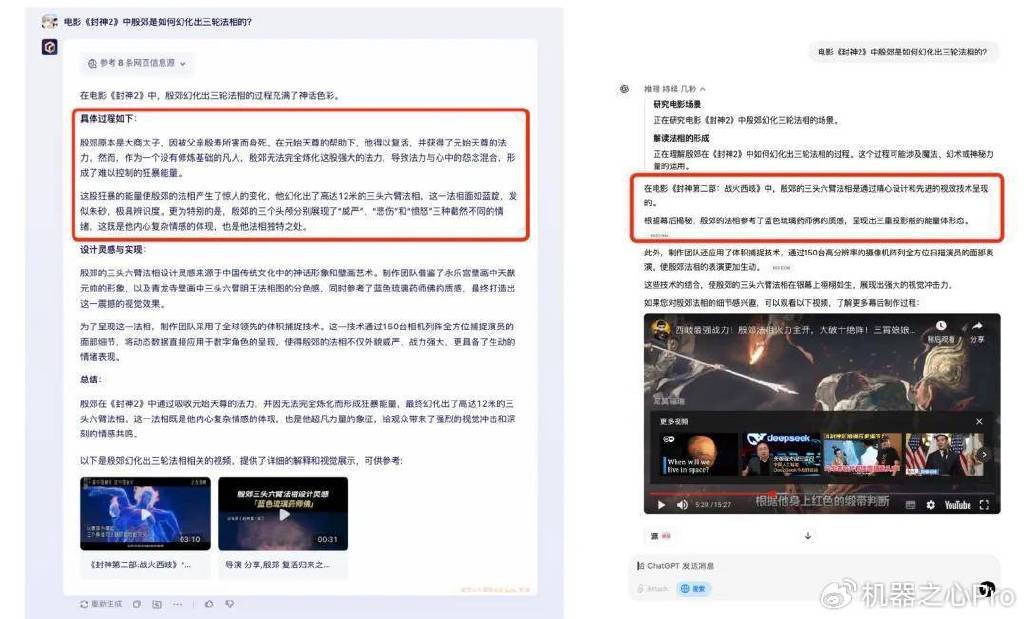
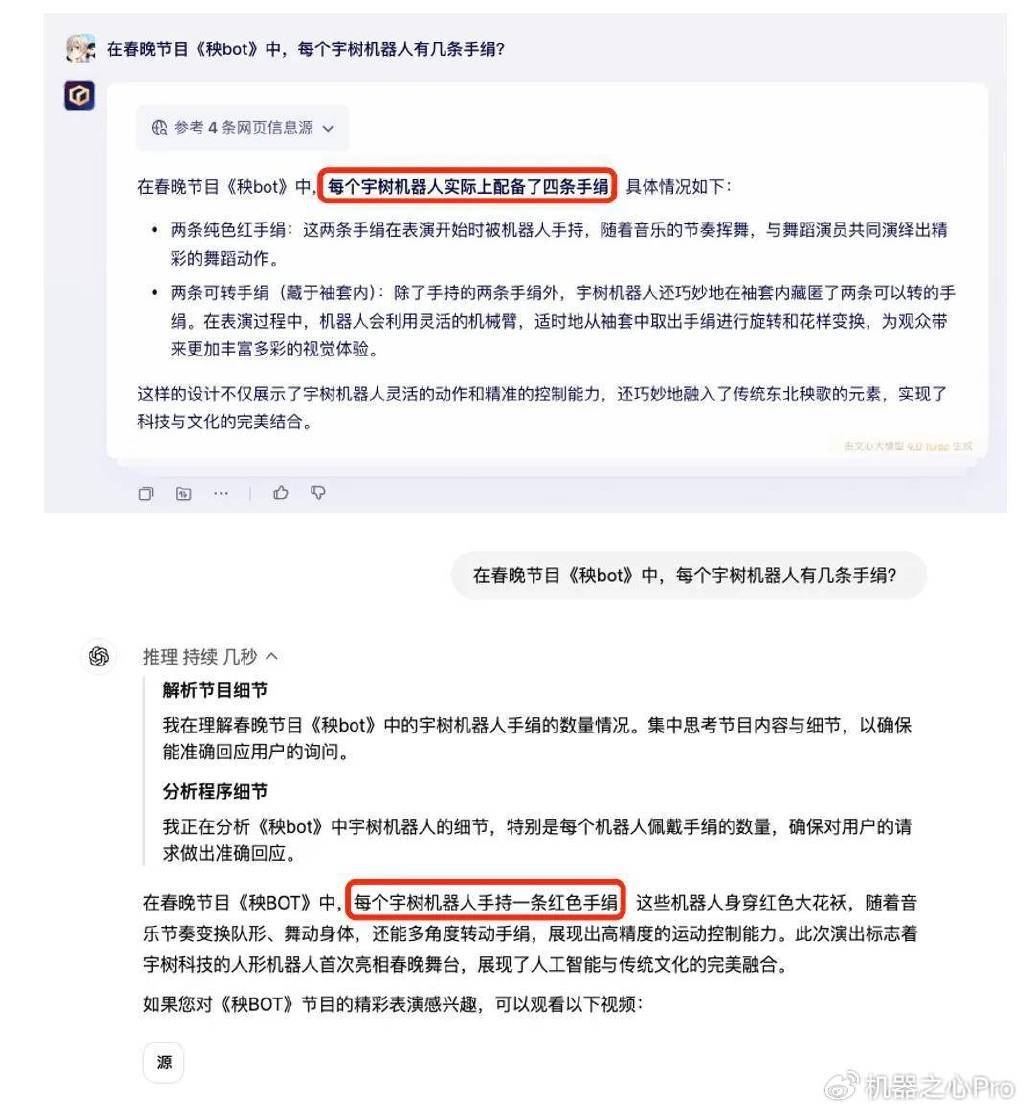

百度在RAG技术上的优势,得益于其在中文深度理解、多模态检索、垂直领域定制化及实时数据整合能力等方面的深厚积累。这使得文心一言在中文互联网、企业服务、政务等场景中更具实用性和竞争力。百度研发的“理解-检索-生成”协同优化的检索增强技术,更是显著提升了大模型技术及应用的效果。
随着DeepSeek等中国大模型厂商的崛起,OpenAI昔日的“技术黑盒”正被逐一破解。从复制Sora到复制o1,中国大模型厂商已经证明了自己的实力。知名AI研究者吴恩达也表示,中国在生成式人工智能方面正在赶超美国。借助Qwen、Kimi、InternVL和DeepSeek等模型,中国正在迅速缩小与美国的差距,并在视频生成等领域取得了领先地位。