近日,五位高校教授齐聚一堂,在线上深入探讨DeepSeek的技术原理和未来方向。这次讨论不仅揭秘了DeepSeek如何通过优化方法提升算力能效,还回应了业界对于复现o1大推理模型、DeepSeek的技术路线和训练流程等多个热点问题的关注。
北京交通大学教授金一担任此次线上分享的主持人,复旦大学教授邱锡鹏、清华大学副教授刘知远、清华大学教授翟季冬以及上海交通大学副教授戴国浩从不同专业角度分享了他们对DeepSeek的见解。
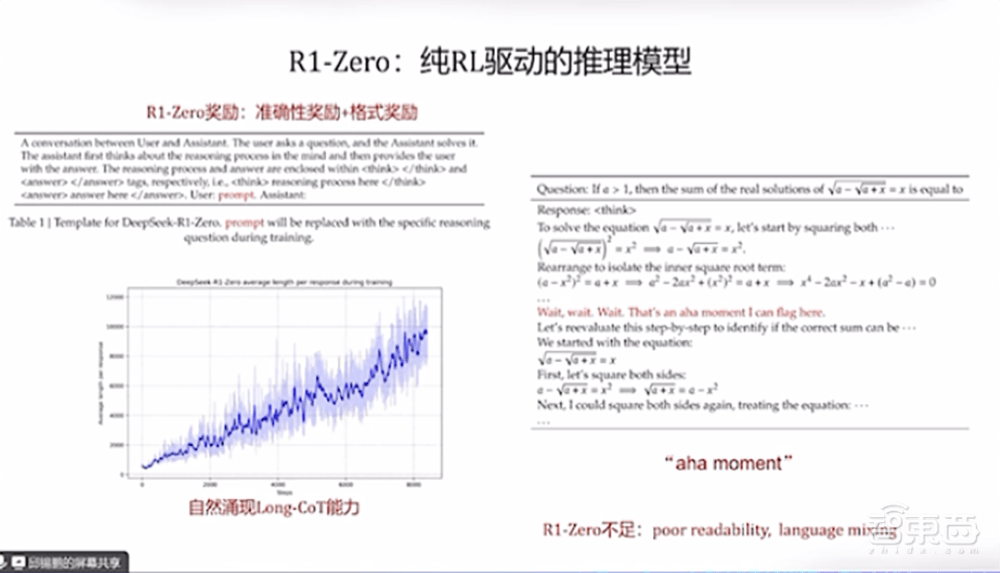
邱锡鹏教授首先介绍了DeepSeek的R1技术路线图,并强调强推理模型的最终目标是实现Agent功能。他指出,OpenAI的o1模型通过强化学习实现了显著的推理能力,而DeepSeek则在此基础上通过策略初始化、奖励设计、搜索和学习等四个方面进行了优化。邱教授特别提到了R1-Zero模型,该模型通过纯强化学习训练,逐步涌现出长思维链能力。
刘知远教授从宏观角度分析了DeepSeek-R1的价值。他认为,DeepSeek是全球首个通过纯强化学习技术复现o1能力的团队,并为行业做出了重要贡献。刘教授指出,DeepSeek-R1的训练流程有两大亮点:一是基于DeepSeek-V1基座模型的大规模强化学习,二是通过深度推理SFT数据和通用SFT数据的混合微调,实现了推理能力的跨任务泛化。
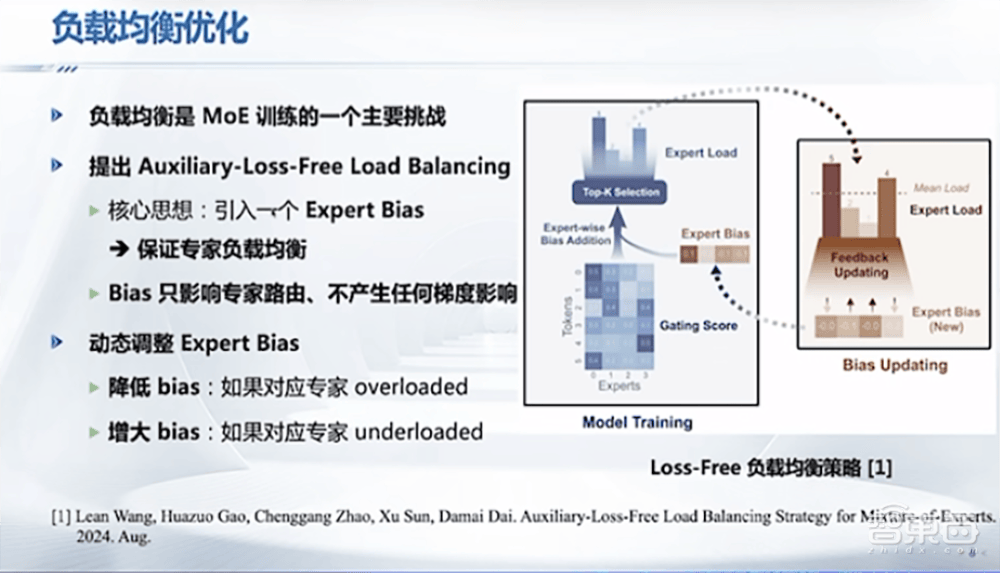
翟季冬教授则详细介绍了DeepSeek在系统软件方面的优化工作。他提到,DeepSeek通过负载均衡、通信优化、内存优化和计算优化等手段,大幅提升了训练效率,从而降低了训练成本。翟教授特别强调了MoE架构在DeepSeek中的应用,以及如何通过创新解决MoE带来的负载均衡问题。
戴国浩教授则就DeepSeek在软硬件协同优化方面的工作进行了讨论。他提到,DeepSeek通过定制的PTX指令和自动调整通信块大小,显著减少了L2缓存的使用和对其他SM的干扰,从而提升了系统性能。戴教授还强调了软硬件协同优化的重要性,并指出未来国产芯片和国内芯片组合将成为大模型优化的新兴热点方向。
在随后的问答环节中,教授们就DeepSeek的技术亮点、成功原因以及对中国大模型未来发展的启示等问题进行了深入探讨。邱锡鹏教授认为,DeepSeek的成功得益于长期积累、软硬件协同创新和高效团队支持。刘知远教授则强调了技术理想主义和长期主义的重要性,并认为DeepSeek为中国AI团队树立了榜样。
翟季冬教授和戴国浩教授则分别从创新和软硬件协同优化的角度分享了他们的见解。翟教授认为创新是社会进步和个人发展的永恒动力,而戴教授则强调了软硬件协同优化在未来AI发展中的重要性。

教授们还就MoE架构是否是最优解、长思维链模型对硬件的需求以及PTX方法的通用性等问题进行了讨论。他们一致认为,未来AI的发展将沿着高效性的方向前进,而创新和软硬件协同优化将是实现这一目标的关键。