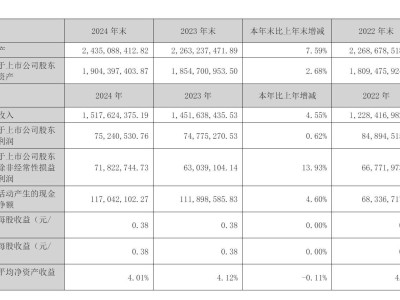
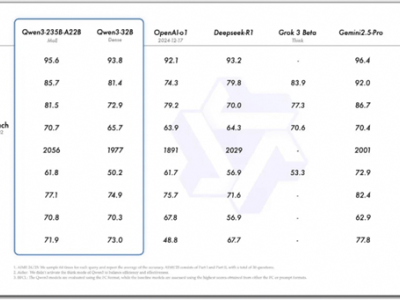
近期,AI领域迎来了一匹黑马——DeepSeek,这款应用在短短两周内迅速崛起,凭借其出色的性能和多元化的应用场景,迅速成为业界的佼佼者。值得注意的是,昆仑芯也宣布加入支持DeepSeek的行列,为其提供了强大的技术支持。
昆仑芯,这一源自百度智能芯片及架构部的企业,自2021年4月完成独立融资后,便以约130亿元的估值,在国内AI加速领域崭露头角。凭借其在体系结构、芯片实现、软件系统及场景应用上的深厚积累,昆仑芯已成为行业内不可忽视的力量。

在蛇年开工的首日,即2月5日,昆仑芯传来喜讯,其新一代产品P800万卡集群已成功点亮,而3万卡集群的点亮也指日可待。这一消息无疑为昆仑芯的发展注入了新的动力。
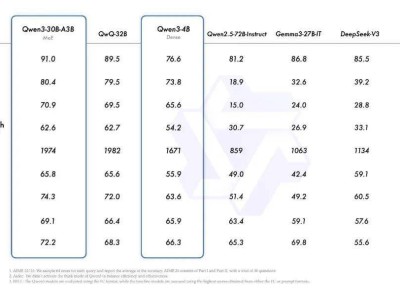
昆仑芯与DeepSeek的合作堪称完美。目前,昆仑芯已完成DeepSeek训练推理的全版本适配,其卓越的性能、一键部署的便捷性以及极高的成本效率,都赢得了用户的广泛赞誉。特别是在DeepSeek-V3/R1上线后不久,昆仑芯便迅速完成了全版本模型的适配,包括DeepSeek MoE模型及其蒸馏的Llama、Qwen等小规模dense模型。
昆仑芯还全面适配了文心系列、Llama、Qwen、ChatGLM、Baichuan等各类大模型的推理和训练任务,其性能优势显而易见。各类大模型任务在昆仑芯平台上运行流畅,为用户提供了卓越的使用体验。


昆仑芯P800在支撑Deepseek系列MoE模型大规模训练任务方面表现出色。它全面支持MLA、多专家并行等特性,仅需32台即可支持模型全参训练,高效完成模型的持续训练和微调。P800的显存规格优于同类主流GPU 20-50%,对MoE架构更加友好。更令人惊喜的是,它率先支持8bit推理,单机8卡即可运行671B模型,这一特性使得P800更易于部署,并显著降低了运行成本。
目前,P800已快速适配支持了Deepseek-V3/R1的持续全参数训练及LoRA等PEFT能力,为用户提供了开箱即用的训练体验。基于昆仑芯完整的软件生态栈,用户只需简单两步,即可轻松实现在昆仑芯P800上进行DeepSeek-V3/R1的推理部署。
首先,用户需要准备镜像和模型资源。昆仑芯P800支持8bit推理,用户只需下载官方权重并使用相应命令进行量化即可。对于其他不同尺寸的蒸馏模型,用户则可通过huggingface进行下载。接下来,用户只需启动服务并配置采样和推理参数,即可开始使用。这一过程与vllm社区的使用方式基本一致,使得用户可以零成本上手。