近期,人工智能领域再次迎来轰动性消息,斯坦福大学和华盛顿大学的研究团队,包括知名学者李飞飞在内,据称以极低的成本——不到50美元的云计算费用,成功研发出一款名为s1的人工智能推理模型。这一消息迅速在AI圈内引发热议。
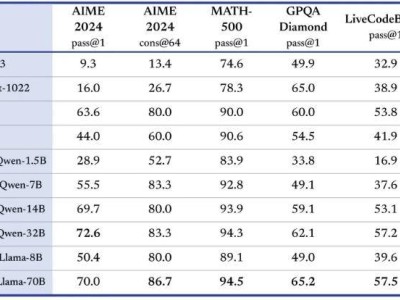
据报道,s1模型在数学和编码能力测试中的表现,与OpenAI的O1模型和DeepSeek的R1模型等业界顶尖推理模型不相上下。这一成就尤为引人注目,因为其所花费的成本相较于通常的高昂研发支出,简直是天壤之别。然而,也有声音指出,s1模型是通过蒸馏法从谷歌的Gemini2.0 Flash Thinking Experimental模型提炼而来。
为了深入了解s1模型的真相,我们详细查阅了相关论文。论文摘要揭示了s1模型并非从零开始构建,而是站在了巨人的肩膀上。研究团队首先精心策划了一个包含1000个问题的小数据集s1K,这些问题均配有详细的推理过程,筛选标准包括难度、多样性和质量。接着,团队开发了一种名为“预算强制”的方法,通过控制模型在测试时的思考时间来优化性能。这种方法包括在模型思考过程中强制终止或延长思考时间,以促使模型修正错误的推理步骤。
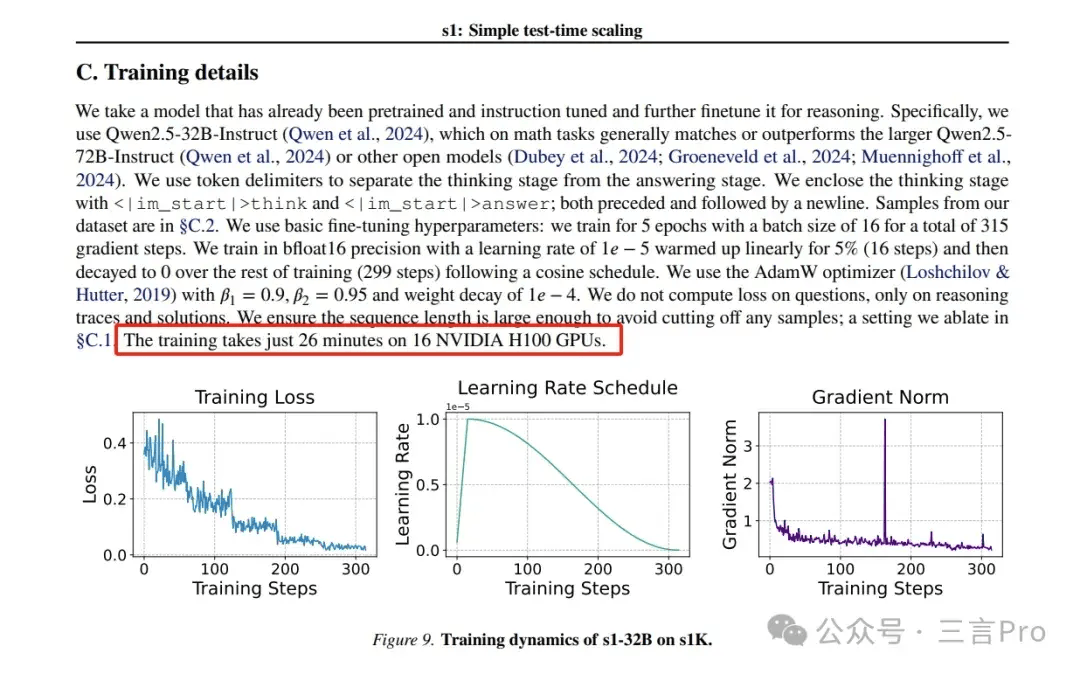
关于“不到50美元”的成本,论文中并未直接提及。这一数字可能源于“训练在16个NVIDIA H100 GPU上只需26分钟”的表述。据财联社报道,这50美元仅为云计算服务费用,不包括服务器、显卡等硬件投入。这些硬件投入已由云厂商承担,因此并未计入总成本。
面对“50美元复刻DeepSeek”的震撼标题,DeepSeek团队也表达了看法。他们认为,s1模型能够以极低成本达到与顶尖模型相当的性能,可能得益于模型架构创新、训练策略突破以及硬件利用革新等多方面因素。同时,他们也肯定了蒸馏监督微调作为一种有效的模型训练方法,在模型压缩、迁移学习和性能提升方面的优势。
据报道,阿里云证实了李飞飞团队以阿里通义千问Qwen2.5-32B-Instruct开源模型为基础,通过监督微调训练出s1-32B模型。该模型在数学及编码能力方面取得了与OpenAI的o1和DeepSeek的R1等尖端推理模型相当的效果,甚至在竞赛数学问题上的表现更为出色。这一案例或许将为未来的AI研究提供新的方向。
然而,值得注意的是,蒸馏监督微调虽然有效,但仍是建立在强大开源模型的基础之上。因此,“50美元复刻DeepSeek”这样的标题确实有些夸大其词。s1模型的成功更多地展示了如何在有限资源下实现高效AI研发的可能性,而非完全颠覆现有的AI研发模式。