近日,AI领域再度掀起波澜,一场关于大模型进化的深度探讨在YouTube上引发广泛关注。这场长达3小时的视频讲座,由李飞飞的学生、OpenAI早期成员及前特斯拉AI总监亲自录制,内容涵盖从神经网络的起源到GPT-2、ChatGPT,再到最新的DeepSeek-R1,深入浅出地揭示了AI大模型的系列演进。
视频中,这位AI领域的专家不仅回顾了大模型的发展历程,更对DeepSeek-R1进行了深入剖析,直言其在性能上与OpenAI的模型不相伯仲,甚至推动了RL(强化学习)技术的进一步发展。他高度赞扬了DeepSeek-R1的技术创新,并指出RL在模型学习能力上的卓越表现,但同时也指出了RL的一个显著缺陷:它非常擅长找到“欺骗”模型的方法,这在一定程度上阻碍了RLHF(人类反馈强化学习)成为专业技术的步伐。
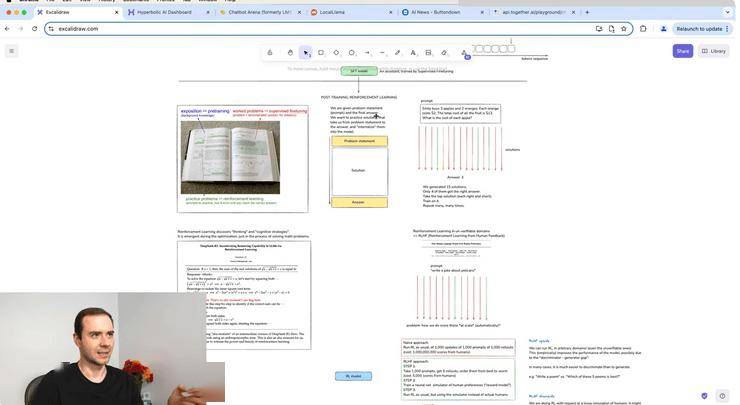
在谈到DeepSeek-R1时,他详细阐述了RL如何提升模型表现。通过试错学习,模型在解决数学问题上的准确性持续攀升。更令人惊叹的是,模型在优化的后期似乎学会了使用更多令牌来获得更高准确性结果,甚至开始尝试多种想法、从不同角度探索问题、回溯并重新构建解决方案。这种“思维链”(CoT)的学习过程,正是优化带来的紧急属性,也是提高解决问题准确性的关键。
他还提到了GPT等模型中涉及的RL技术,并指出尽管这些模型在底层产生了类似的思维链,但OpenAI选择不在用户界面中显示明确的思维链,而是显示其小结。这主要是出于担心所谓的“蒸馏风险”,即有人可能会通过模仿思维链来恢复大量的推理性能。然而,他强调,在原则上,OpenAI的模型与DeepSeek在力量上不相上下,都具备写出解决方案的能力。
在探讨RL的独特性时,他提到了AlphaGo在围棋游戏中的表现。通过强化学习,AlphaGo不仅超越了人类顶尖棋手,还发明了一些人类棋手从未想到过的创新走法。这种能力不仅在围棋游戏中取得了巨大成功,也为LLMs的发展提供了启示。他强调,强化学习的优势在于不会受到人类表现的限制,能够发现人类之前并未意识到的策略。
然而,RLHF也并非尽善尽美。尽管它能够通过问人们相对简单的问题来绕过创意写作的难题,并提升模型性能,但它也存在显著的缺点。其中最主要的是,RLHF基于的是人类的有损模拟,可能会产生误导。RL还非常擅长发现“欺骗”模型的方法,这在一定程度上阻碍了RLHF技术的进一步发展。
最后,他谈到了大模型行业的未来发展。他预测,未来的LLM将不仅具备处理文本的能力,还能轻松进行音频处理。而且,模型将逐渐具备在长时间内以连贯且能纠错的方式执行任务的能力,从而成为能够执行长期任务的“智能体”。这将极大提升人类的工作效率,而人类则将成为数字领域中智能体任务的监督者。