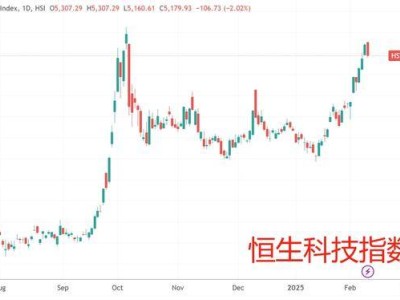
在科技界的春节氛围中,一款名为DeepSeek的AI大模型如同一颗石子投入平静的湖面,激起了层层涟漪。不少国内大模型领域的从业者,在假期前夕就感受到了来自DeepSeek的冲击。
一位不愿透露姓名的从业者表示,当DeepSeek横空出世时,他和同事们正紧锣密鼓地讨论着新一年的工作计划。“我半开玩笑地说,真想去DeepSeek工作。说实话,我认为它的产品能力与ChatGPT不相上下,如果给ChatGPT打80到90分,那国内其他大模型我只能给一半分数。”他坦言。
这家被视为国内大模型行业先行者的公司,尽管在过去一年中取得了不少商业化应用的成果,但在面对DeepSeek时,仍显得有些力不从心。该从业者指出,DeepSeek的两大亮点让他印象深刻:一是其卓越的产品能力,使得用户在使用时几乎无需费心调整提示词,就能得到流畅且准确的回答;二是它为整个行业带来了希望,尤其是在商业化发展方面。
据他描述,DeepSeek不仅能够理解各种复杂的指令,还能在版权保护方面展现出意识,拒绝提供未经授权的下载地址。这种体验,让他对DeepSeek的产品能力赞不绝口。同时,他也认为DeepSeek以较低的成本取得了与OpenAI相当的效果,为商业化发展开辟了新路径。
然而,并非所有人都对DeepSeek持乐观态度。另一位从业者王锐表示,他和家人在测试DeepSeek时遇到了几个小错误,这让他对DeepSeek的印象大打折扣。他认为,市场主流的大模型产品能力并不逊色于DeepSeek,而所谓的“大模型幻觉”问题依然存在。
王锐指出,DeepSeek的功绩在于开创了全新的模型训练模式,加速了AI行业的迭代,并推动了AI产品向C端用户的拓展。这一点,正是2024年国内各家大模型公司努力的方向。随着C端用户逐渐成为大模型的重要目标群体,如何推出适合C端用户的AI应用级产品,探索有效的商业模式,成为行业关注的焦点。
事实上,已经有不少公司在AI to C市场取得了显著成果。夸克和豆包等应用成功迈入“亿级俱乐部”,为行业树立了榜样。而阿里引进全球顶尖人工智能科学家许主洪教授负责AI To C业务,也进一步表明了头部玩家在这一领域的布局决心。
尽管DeepSeek吸引了大量下载,但王锐认为其中不乏跟风者。他指出,真正的产品力对比才是关键,而情绪带来的用户是否会成为产品的核心高频用户,仍然是个未知数。
与此同时,DeepSeek的崛起也让国内大模型领域的竞争格局发生了微妙变化。一些原本在海外知名度不高的国内大模型公司,现在面临着来自DeepSeek的直接竞争。有从业者表示,DeepSeek已经将战线拉到了与OpenAI、Gemini等海外巨头齐平的水平,对海外巨头形成了降维打击。
DeepSeek的性价比也引发了业界的广泛关注。有从业者指出,DeepSeek-R1的成本仅为国外大模型的三十分之一,这一说法虽然尚未得到证实,但已经让业界对大模型的期待回归理性。各大厂主力大模型纷纷降价,价格战愈演愈烈。
然而,并非所有人都认为DeepSeek已经无敌于天下。有声音指出,DeepSeek目前可能更适合中小企业,因为中小企业在选择大模型时更注重性价比。同时,也有报道指出斯坦福大学和华盛顿大学的研究人员以低廉的云计算费用训练出了一个与DeepSeek-R1不相上下的AI推理模型,进一步证明了性价比的重要性。
无论如何,DeepSeek的崛起已经让国内大模型领域的竞争变得更加激烈。对于普通企业和个体用户来说,能够以较低的成本使用能力更强的AI产品无疑是一件好事。而对于从业者而言,在这个中国AI军团开始真正登上国际舞台肉搏的时代,痛苦和快感将成为他们必须面对的一体两面。