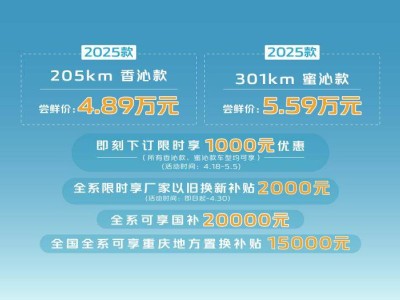
近期,AI领域的一颗新星——DeepSeek-R1,以其卓越的性能和惊人的用户增长速度,迅速在科技圈内引起了轰动。这款模型通过采用稀疏激活的MoE架构、MLA注意力机制优化以及混合专家分配策略等创新技术,不仅显著提升了训练和推理效率,还大幅度降低了API调用成本,树立了行业新标杆。
尤其DeepSeek-R1在发布后的短短7天内,用户数便突破了1亿大关,这一速度远超OpenAI的ChatGPT,后者达到相同里程碑用了整整2个月。这一成就不仅彰显了DeepSeek-R1的强大吸引力,也预示着AI市场即将迎来新一轮的竞争与变革。

随着DeepSeek-R1的火爆,网络上涌现了大量关于其本地部署的教程。然而,这些教程往往只强调DeepSeek-R1的强大功能,却对“蒸馏版”与“满血版”之间的性能差异语焉不详。事实上,目前公开发布的小尺寸DeepSeek-R1模型,如7B和32B版本,均是通过Qwen或Llama从R1中蒸馏而来,以适应不同性能设备的调用需求。
换句话说,这些较小尺寸的模型虽然在某种程度上保留了R1的特性,但更像是“牛肉风味肉卷”与“牛肉卷”的区别,它们在推理功能上虽能勉强模仿,但性能上却大打折扣。随着模型尺寸的缩小,性能差距愈发明显。
为了直观展示这种差异,我们进行了一系列测试。在语言能力测试中,我们要求7B、32B和671B版本的DeepSeek-R1分别用“新年快乐万事如意”创作一首藏头诗。结果,7B版本不仅未能成功“藏头”,输出的内容也毫无诗意,甚至夹杂了英文。相比之下,32B版本虽然押韵上有所欠缺,但七言律诗对仗工整,逻辑清晰。而“满血版”671B则更胜一筹,不仅对仗工整、韵脚得体,还附带了诗词赏析,展现了深厚的文化底蕴。

在联网总结测试中,我们进一步探索了不同尺寸模型对网络内容汇总的能力。通过以杜甫的《登高》为测试内容,我们发现7B版本的表现虽然偶尔优秀,但更多时候会出现理解偏差。32B版本则相对稳定,对诗词内容的理解准确性有所提高。而“满血版”671B则能完整展示诗句内容,并增加点评与背景陈述,使回答更具知识性和专业性。
在逻辑推理测试中,我们使用了经典的“鸡兔同笼”问题和一道更复杂的几何题来考验模型。令人惊讶的是,无论是7B还是32B版本,都能正确解答这些问题,显示出在数学运算能力上蒸馏版尽可能保留了R1模型的优点。
然而,在代码能力测试中,7B版本的DeepSeek-R1生成的贪吃蛇游戏程序存在bug,无法正常运行。而32B版本则能生成可正常运行的游戏程序,玩家可以通过键盘方向键控制蛇的移动,同时面板能正常计分。
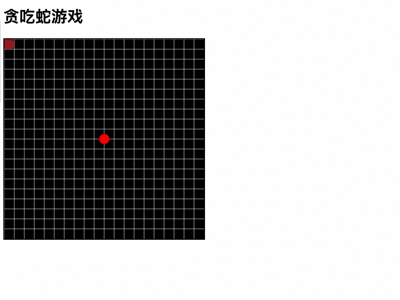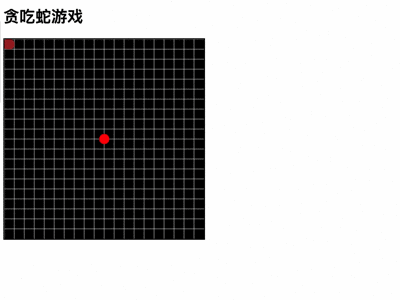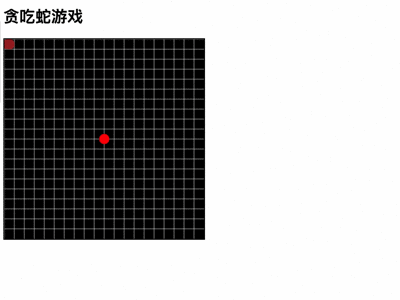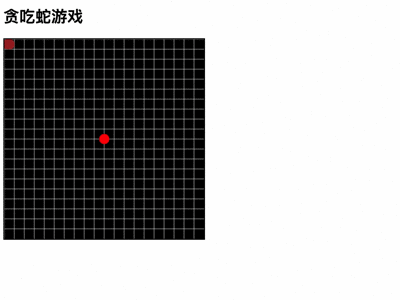

尽管DeepSeek-R1的7B和32B版本在某些方面表现出色,但与“满血版”671B相比仍存在明显差距。因此,本地部署更适合用于搭建私有数据库或供有能力的开发者进行微调与部署。对于一般用户而言,无论从技术还是设备门槛都相对较高。
官方测试结论显示,32B版本的DeepSeek-R1大约能实现90%的671B版本性能,且在部分场景下效果略优于OpenAI的o1-mini。然而,在实际体验中,32B以上模型才勉强具备本地化部署的可用性,更小尺寸的模型在基础能力上过于薄弱,甚至不如同尺寸的其他模型。
运行32B版本的DeepSeek-R1模型,官方建议配置64GB内存和32-48GB显存,再配合对应的CPU,一台电脑主机的价格大约在2万元以上。即使以最低配置运行,价格也要超过万元。本地化部署后还需为模型增加联网功能或本地化数据库,否则模型内的数据会与互联网脱节。
因此,对于大多数普通用户而言,费劲心力搭建的本地大模型可能并不如市面上主流的免费大模型产品来得简单、方便、效果好。DeepSeek系列模型的成功不仅改变了中美技术竞争格局,更对全球科技创新生态产生了深远影响。然而,面对这场科技变革,如何将技术创新优势转化为持续的竞争能力,将是未来面临的关键挑战。