在人工智能领域,一项新的突破正引起广泛关注。北京大学与香港科技大学的研究团队携手,基于他们自研的全模态框架Align-Anything,成功将原本专注于纯文本模态的Deepseek R1系列模型拓展至图文模态,推出了名为Align-DS-V的多模态版本。
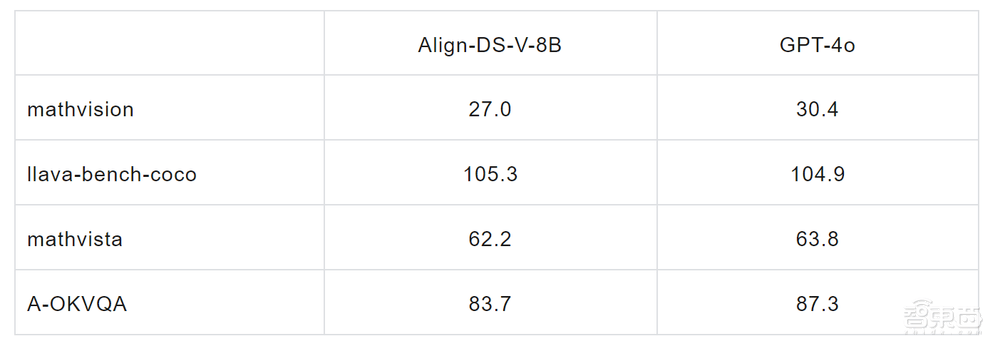
这一创新不仅标志着Deepseek R1系列模型在功能上的重大飞跃,更在部分视觉理解评测集上的表现超越了GPT-4,为人工智能的多模态理解与应用开辟了新的道路。
此次合作中,北京大学的指导老师杨耀东教授发挥了关键作用。作为北京大学人工智能研究院的助理教授,他同时也是北京具身智能初创公司灵初智能与北大联合成立的具身灵巧操作联合实验室的首席科学家。在杨教授的带领下,研究团队仅在一周之内就完成了Deepseek R1向图文模态的扩展,并取得了令人瞩目的成果。
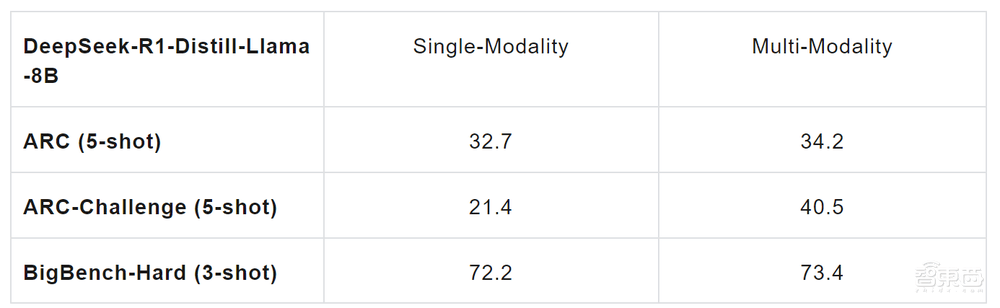
团队在探索过程中还意外发现了模态穿透对模型文本模态推理能力的提升效果。经过多模态训练后,模型在文本模态任务上的表现有了显著提升,特别是在科学任务、复杂推理以及数学代码处理等方面。
Align-DS-V的多模态强推理能力被视为VLA模型(视觉语言动作模型)大脑端的核心。这一能力不仅提升了模型的理解和推理水平,还为VLA模型的小脑端控制器微调提供了可能,从而实现更高的成功率、泛化性和鲁棒性。目前,Align-Anything框架以及DeepSeek-R1的多模态版本Align-DS-V均已开源,供全球研究者共同探索与进步。
Align-Anything框架的设计初衷是实现全模态大模型与人类意图和价值观的对齐。它支持从文本、图片、视频、音频四大基本模态衍生出的任意模态模型的对齐微调,并验证了框架对齐算法的正确性。该框架具有高度的模块化、扩展性和易用性,为研究者提供了极大的便利。

为了进一步验证全模态推理大模型的实际应用能力,研究团队对Align-DS-V进行了本地化对齐,使其适应粤语、英语和普通话混合语言输入,并整合了香港本土生活场景如港铁动态、台风预警及八达通缴费等。这一举措不仅展示了Align-DS-V的灵活性,也为其在更多实际应用场景中的推广奠定了基础。

在面对包含繁体字的图文数学问题时,Align-DS-V展现出了其强大的多模态理解能力。它能够准确联动图文模态信息,使用严密的数学推导展示求解过程,进一步证明了其在复杂任务处理上的卓越表现。

随着Align-DS-V的成功推出,北大-灵初联合实验室已经在VLA领域展开了更深度的探索。他们计划利用多模态推理模型的跨模态穿透能力,实现action穿透,从而打造出真正高效的VLA模型。这一创新不仅有望推动具身智能技术的快速发展,还将为企业降低技术门槛,促进更多力量向更底层的运动控制领域集中。