近日,AI大模型DeepSeek-R1的使用难题成为了用户们关注的焦点。此前,用户主要通过云服务或本地部署来使用这款模型,但云服务频繁宕机,而本地部署的版本多为参数量大幅缩水的蒸馏版。对于一般用户而言,在普通硬件上运行DeepSeek-R1的满血版几乎是不可能的任务,即便是开发者,租赁服务器的成本也令人望而却步。
然而,这一局面即将迎来重大改变。清华大学KVCache.AI团队与趋境科技携手发布的KTransformers开源项目,近日宣布取得了突破性进展,成功破解了千亿级大模型本地部署的难题。这一突破标志着大模型推理将摆脱“云端垄断”,走向更加普惠化的道路。
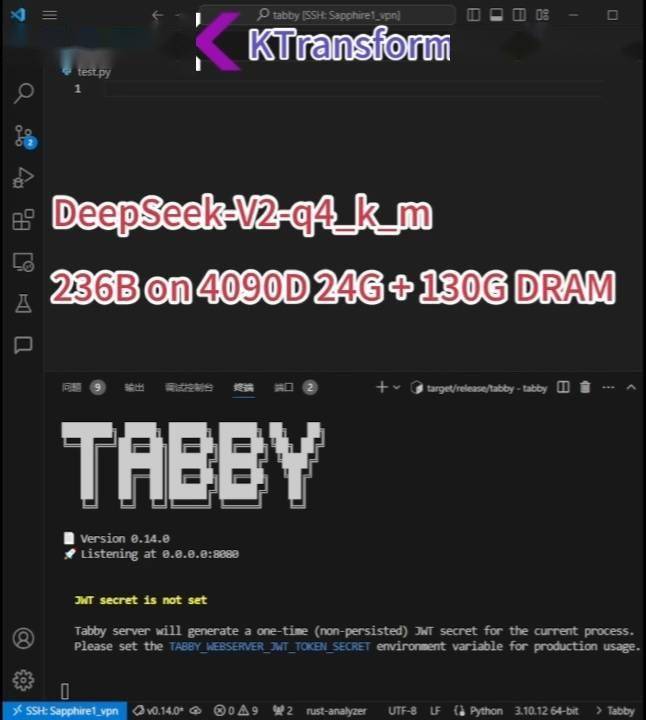
据KTransformers团队介绍,他们已在配备24GB显存和382GB内存的PC上成功实现了DeepSeek-R1、V3的671B满血版的本地运行,速度提高了3至28倍。不仅如此,他们还宣布支持更长的上下文(24GB单卡支持4~8K),并实现了15%的加速,每秒最多可处理16个Tokens。
KTransformers作为一个以Python为中心的灵活框架,其核心设计注重可扩展性。用户只需通过一行代码即可实现和注入优化模块,从而访问兼容Transformers的界面、符合OpenAI和Ollama标准的RESTful API,甚至是类似ChatGPT的简化网页用户界面。这一技术的推出,彻底改写了AI大模型依赖昂贵云服务器的历史格局。

DeepSeek-R1基于混合专家(MoE)架构,通过将任务分配给不同专家模块,并在每次推理时仅激活部分参数来提高效率。KTransformers团队创新性地将非共享稀疏矩阵卸载至CPU内存处理,并结合高速算子优化,成功将显存需求从传统8卡A100的320GB压缩至单卡24GB。这一创新使得普通用户只需24G显存即可在本地运行DeepSeek-R1、V3的671B满血版,预处理速度最高可达286 tokens/s,推理生成速度最高能达到14 tokens/s。

KTransformers团队还通过减少CPU/GPU通信断点,实现单次解码仅需一次完整的CUDA Graph调用,生成速度优化至14 tokens/s,功耗仅为80W,整机成本约2万元,仅为传统8卡A100方案的2%。经过开发者实测,使用RTX 3090显卡和200GB内存配置,结合Unsloth优化,Q2_K_XL模型推理速度可达9.1 tokens/s,实现了千亿级模型的“家庭化”运行。
值得注意的是,KTransformers并非一个单纯的推理框架,也不限于DeepSeek模型。它可以兼容各式各样的MoE模型和算子,能够集成各种算子并进行各种组合的测试。同时,KTransformers还提供了Windows、Linux平台的支持,感兴趣的用户可自行尝试。但要想使用KTransformers,也需要满足一定的硬件条件,包括英特尔至强Gold 6454S 1T DRAM CPU、RTX 4090D(24G VRAM)GPU、标准DDR5-4800服务器DRAM(1TB)内存以及CUDA 12.1或更高版本。