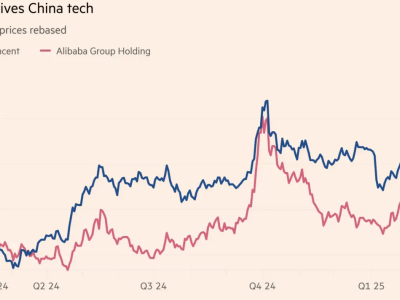
在自然语言处理领域,一个引人瞩目的现象正在显现:传统的通过增加模型规模和数据量来提升性能的Scaling Law似乎已逼近瓶颈。业界开始担忧,单纯依赖这种策略或许已难以带来显著的性能飞跃,低精度训练和推理正使得模型性能提升的边际效益逐渐递减。然而,在自然语言处理遭遇挑战的同时,多模态模型领域却似乎尚未触及这一限制。
多模态数据,涵盖图像、视频、音频等多种类型,因其信息丰富度、处理方法和应用领域的复杂性,难以达到大规模训练的标准。因此,Scaling Law在多模态领域尚未得到充分验证。但这一现状即将发生改变。清华系大模型公司生数科技最新发布的Vidu 1.5,正引领多模态领域迈向新的发展阶段。
Vidu 1.5通过持续的规模扩展(Scaling Up),已达到了一个关键的“奇点”时刻,涌现出了强大的“上下文能力”。这一能力使模型能够理解并记忆输入的多主体信息,展现出对复杂主体更为精准的控制。无论是细节丰富的角色还是复杂的物体,仅需上传不同角度的三张图片,Vidu 1.5便能确保单主体形象的高度一致。
Vidu 1.5的突破不仅限于单主体控制,还实现了多主体之间的一致性。用户能够上传包含人物角色、道具物体、环境背景等多种元素的图像,Vidu能够将这些元素无缝融合,实现自然交互。这一能力标志着多模态模型在主体一致性方面取得了重大进展。
Vidu在主体一致性方面的成就,不仅得益于Scaling Law的发挥,更源于其采用的无微调、大一统的技术架构方案。当前主流的视频模型为实现一致性,大多采用在预训练基础上针对单个任务进行微调的LoRA方案。而Vidu的底层模型则跳出了这一框架,做出了开拓性的改变。这一改变与生数科技一贯坚持的通用性理念相契合,通过统一的底层模型技术架构,无需单独进行数据收集、标注和微调,仅需1到3张图即可输出高质量视频。
回顾大语言模型的发展历程,从GPT-2到GPT-3.5的质变,同样实现了从预训练+特定任务微调向统一框架的突破。Vidu 1.5的推出,标志着多模态大模型正经历着类似于GPT-3.5的时刻。这一突破不仅体现在技术上,更在于设计理念上的革新。
生数科技CTO鲍凡表示,公司不会盲目追随Sora等已有模型的路线,而是从一开始就瞄准通用多模态大模型的目标,进行自主研发。从全球首个基于Diffusion的Transformer架构U-ViT的发布,到首次实现用统一架构处理泛化任务,生数科技不仅拥有先发优势,更具备持续突破的能力。Vidu与业界其他视频生成模型相比,已形成明显的技术代差。
在主体一致性这一难题上,Vidu取得了显著成果。鲍凡比喻道,这就像制造一台好的发动机,虽然知道其重要性,但实现起来却异常艰难。包括Sora在内的国内外视频模型,在主体一致性方面均未取得突破。而Vidu则从上线之初就主打解决一致性问题,并逐步拓展到对单主体整体形象的控制,直至最新版本的Vidu 1.5,已能够实现对单主体不同视角的高度精准控制,并攻破多主体控制的难题。
Vidu的技术方案与业界主流存在显著差异。其他家仍局限于预训练+LoRA微调的方案,存在数据构造繁琐、训练时间长、易过拟合、无法捕捉细节等缺点。而生数则通过统一的底层模型技术架构,无需单独进行数据收集、标注和微调,仅需少量图片即可输出高质量视频。这一架构的统一性不仅体现在问题形式上,更体现在底层设计上,与Sora的DiT架构存在本质区别。
随着高质量数据的一同扩展,Vidu在底层视频生成模型上也观察到了类似于大语言模型的智能涌现现象。例如,Vidu 1.5能够融合不同主体,创造出全新的角色,这是之前未曾预料到的能力。其智能涌现还体现在上下文能力提升和记忆能力增强上,能够实现对视频中角色、道具、场景的统一控制。
Vidu在上下文能力方面的迭代节奏紧凑,从初期仅能参考单一主体的面部特征,到现在能参考多个主体,未来预期可以实现参考拍摄技巧、运镜、调度等更多因素。这一过程中,参考对象从具体到抽象,要求和难度逐渐提升。由于目前还没有针对视频模型上下文能力的开源解决方案,Vidu 1.5在这一领域形成了自己的技术壁垒。