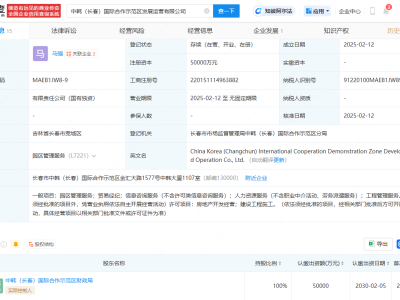
DeepSeek公司近期宣布了一项技术创新,正式推出了名为NSA(Native Sparse Attention)的新型稀疏注意力机制。这一机制专为超快速长上下文训练与推理设计,实现了硬件对齐与原生可训练性。
NSA的核心组成部分别具一格,涵盖了动态分层稀疏策略、粗粒度token压缩以及细粒度token选择。这些组件的协同作用,使得NSA在提升性能的同时,也优化了现代硬件设计。

据DeepSeek官方介绍,NSA机制不仅能够加速推理过程,显著降低预训练成本,而且在性能上并未做出妥协。在通用基准测试、长上下文任务以及基于指令的推理场景中,NSA的表现与全注意力模型相比,要么相当,要么更胜一筹。
这一创新技术的推出,对于深度学习领域而言无疑是一个重大突破。通过优化硬件设计与训练效率,NSA为大规模语言模型的应用开辟了新路径,使得长上下文处理和快速推理成为可能。
DeepSeek还提供了关于NSA机制的详细论文链接,供相关领域的研究人员和开发者深入了解和探索。