近日,科技界迎来了一次重大突破,马斯克的人工智能初创公司xAI正式推出了其最新的聊天机器人——Grok 3。这款产品的发布不仅引起了业界的广泛关注,还因其背后的巨大投入和技术革新成为了热议的话题。
据悉,马斯克和他的团队在Grok 3的训练上投入了大量资源,动用了20万块GPU,这一数字足以让人瞠目结舌。他们声称,这一前所未有的训练规模使得Grok 3在高级推理能力上超越了现有的众多人工智能模型。这无疑给当前的人工智能领域带来了一股强劲的新势力。
在直播发布会上,马斯克详细介绍了Grok 3的训练历程。从最初的10万张H100 GPU,到训练进行到第92天时的20万张,这一规模的扩张速度之快,令人叹为观止。而Grok 3的实力也的确没有辜负这份投入,它在数学、科学、代码等多个数据集上的表现均超越了GPT-4o、DeepSeek-V3等非推理模型。
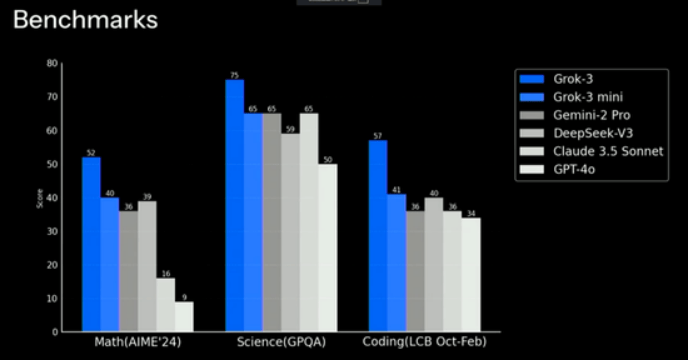
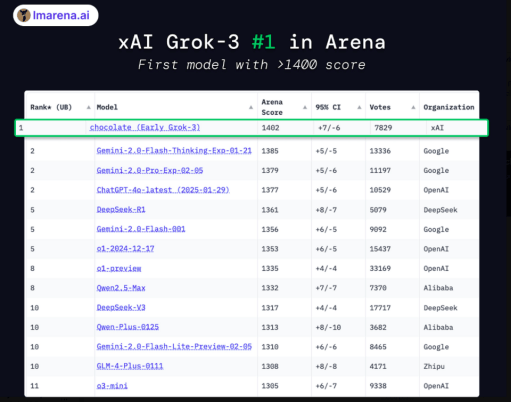
在LMSYS Arena排行榜上,Grok 3更是以Elo评分超1400的优异成绩位列榜首,断层式领先其他模型。这一成绩无疑是对xAI团队努力与投入的最好证明。而Grok-3 mini版本也展现出了强大的实力,其性能基本上领先或媲美其他闭源/开源模型。
除了在数学和科学领域展现出的卓越能力外,Grok 3还在自动化游戏开发方面展现出了巨大潜力。在发布会上,xAI团队要求Grok 3现场创造一款融合《俄罗斯方块》和《宝石迷阵》的新游戏。令人惊讶的是,Grok 3不仅迅速生成了Python脚本定义了游戏的元素,还呈现出了独特的玩法,这一表现让在场的所有人都为之惊叹。
Grok 3还包含一个名为Big Brain的功能,这是一个专门用于推理的模型模式。它能够在处理查询时进行更深入的思考,从而得出更加准确的答案。马斯克在发布会上幽默地表示,17个月前,最初的Grok模型几乎不能解决高中问题,而现在它已经进步了很多,已经准备好“上大学”了。
然而,尽管Grok 3取得了如此巨大的成功,但其背后的巨大投入也引发了业界的热议。与DeepSeek通过算法优化和高效的资源利用方式大幅降低对高端GPU的依赖不同,马斯克选择了直接投入大量GPU来快速推出Grok 3。这一做法虽然换来了LMSYS Arena排行榜上41分的提升,但也引发了关于性价比的讨论。
尽管如此,马斯克疯狂砸钱的举动或许有着更深远的考量。在当前的人工智能领域,任何模型的训练都离不开GPU。而马斯克的20万块GPU不仅是为了快速推出Grok 3,更可能是为了后续保持快速迭代的能力,从而在人工智能领域保持领先地位。