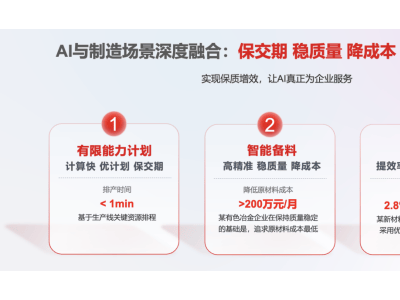
北京时间2月18日,科技界迎来了一场万众瞩目的盛事——马斯克携手xAI团队,在直播中隆重揭晓了Grok系列的最新力作:Grok3。在这场发布会之前,凭借马斯克无休止的预热与各式信息的释放,全球观众对Grok3的期待值已被推向顶峰。
马斯克在直播中,满怀信心地展示了Grok3在数学、科学与编程领域的卓越表现,甚至预言它将助力SpaceX的火星探索任务,未来三年内有望带来诺贝尔奖级别的科学突破。然而,这些豪言壮语能否站得住脚,还需时间的检验。
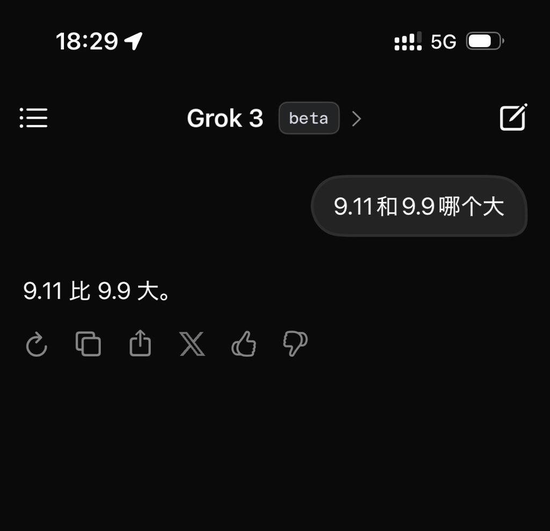
在发布会后不久,不少测试者便迫不及待地体验了Grok3的Beta版本,并提出了一些经典难题来考验这位“AI天才”。例如,当被问及“9.11与9.9哪个大”这一看似简单的问题时,Grok3却未能给出正确答案,令人大跌眼镜。这一测试迅速在网络上发酵,引发了广泛讨论。
不仅如此,海外网友也纷纷发起类似测试,发现Grok3在回答基础物理、数学问题时同样捉襟见肘,如“比萨斜塔上两个球哪个先落下”这样的问题也难住了它。一时间,“天才不愿回答简单问题”的调侃之声四起。
更为尴尬的是,在xAI发布会直播现场,马斯克演示Grok3分析他声称常玩的游戏《流放之路2》的职业与升华效果时,Grok3给出的答案竟大部分是错误的,而马斯克却未察觉这一明显失误。这一插曲不仅成为网友嘲讽马斯克游戏水平的“实锤”,也让人们对Grok3的可靠性产生了严重质疑。
事实上,早在发布会前的预热阶段,马斯克就曾自信满满地表示,xAI即将推出超越DeepSeek R1的AI模型。然而,经过众多测试者的亲身体验,Grok3的表现并未明显优于DeepSeek R1或o1-Pro等其他主流模型。甚至有测试者指出,Grok3在某些方面的表现甚至不如前辈。

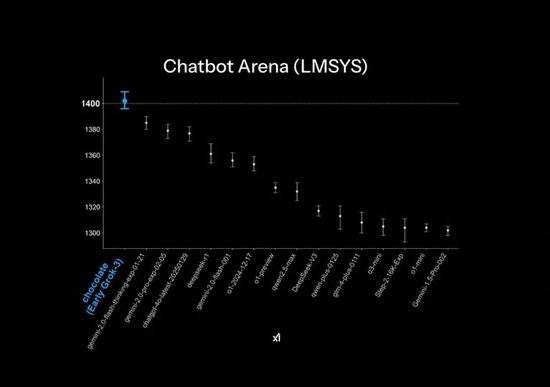
尽管在官方PPT中,Grok3在大模型竞技场Chatbot Arena中实现了“遥遥领先”的战绩,但这背后却隐藏着一些作图技巧。榜单的纵轴仅列出了1400-1300分段的排名,使得原本微小的差距在PPT中显得异常显著。而实际的模型跑分结果显示,Grok3与DeepSeek R1及GPT4.0的差距仅为1%-2%。
值得注意的是,为了训练出Grok3这位“AI天才”,马斯克不惜耗费了巨额资源。据他透露,Grok3的训练使用了超过20万张H100 GPU,总训练小时数达到两亿小时。这一数字令人咋舌,也引发了业界对于模型训练未来走向的热烈讨论。然而,有网友对比发现,使用2000张H800训练两个月的DeepSeek V3,在算力消耗上仅为Grok3的263分之一,而两者在榜单上的差距却不到100分。
这一系列事实表明,随着模型体积的不断增大,性能提升的边际效应已愈发明显。即便是拥有海量高质量数据的xAI,也遭遇了优质训练数据不足的瓶颈。面对这一困境,马斯克在社交媒体上不断强调当前版本仅为测试版,完整版将在未来几个月推出,并亲自化身产品经理,鼓励用户反馈问题。
然而,Grok3的表现无疑给那些试图通过“大力出奇迹”训练出更强大模型的后来者敲响了警钟。随着模型参数体积的飞涨,训练成本也在飙升。如何在有限的资源下实现模型性能的最大化,已成为业界亟待解决的问题。或许,正如OpenAI前首席科学家Ilya Sutskever所言,“预训练模型的时代即将结束”,未来的AI系统需要具备真正的自主性和类人脑的推理能力。