在全球科技界聚焦马斯克Grok-3巨型GPU集群之际,中国的大模型技术公司正悄然加速技术创新步伐。
近期,一项名为Native Sparse Attention(NSA)的研究成果吸引了业界目光。这项技术由梁文锋等专家亲自参与研发,融合了算法与硬件的双重优化,旨在突破长上下文建模中的计算瓶颈。NSA技术不仅成功将大语言模型处理64k长文本的速度提升了最高11.6倍,还在通用基准测试中超越了传统全注意力模型的性能。这一突破证明,通过算法与硬件的协同创新,可以在保持模型性能的同时,极大提升长文本处理效率。
紧接着,Kimi公司也推出了自家的稀疏注意力技术——MoBA(Mixture of Block Attention)。该技术由月之暗面、清华大学及浙江大学的研究团队共同研发,旨在将全上下文划分为多个块,每个查询令牌学习关注最相关的键值块,以实现高效的长序列处理。
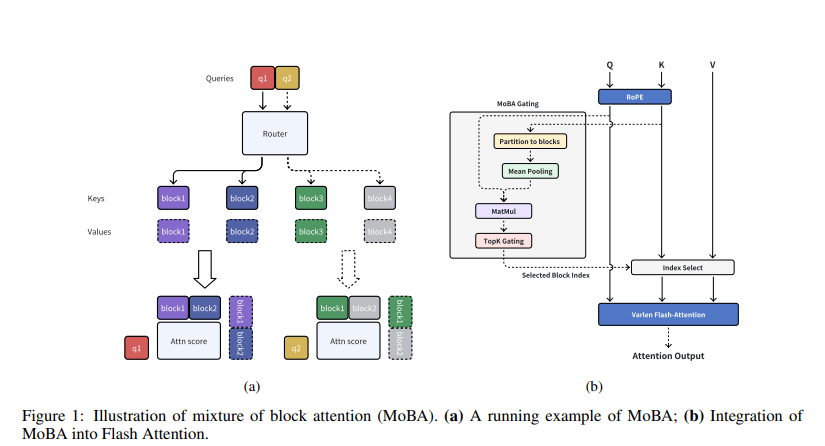
据相关论文介绍,MoBA技术在各种长文本处理任务中,能够保持相近性能的同时,显著降低注意力计算的时间和内存消耗。在1M token的测试中,MoBA的速度比全注意力快了6.5倍;在处理超长文本(如1000万token)时,MoBA的优势更加明显,实现了16倍以上的加速。
MoBA的核心创新在于可训练的块稀疏注意力机制,它通过将输入序列划分为多个块,每个查询令牌动态选择最相关的几个块进行注意力计算,而非传统方法中的全局计算。MoBA还引入了无参数top-k门控机制,确保模型只关注信息量最大的部分,同时支持在全注意力和稀疏注意力模式之间无缝切换。
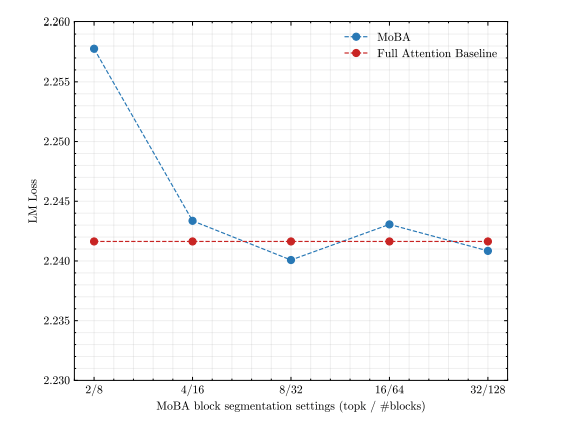
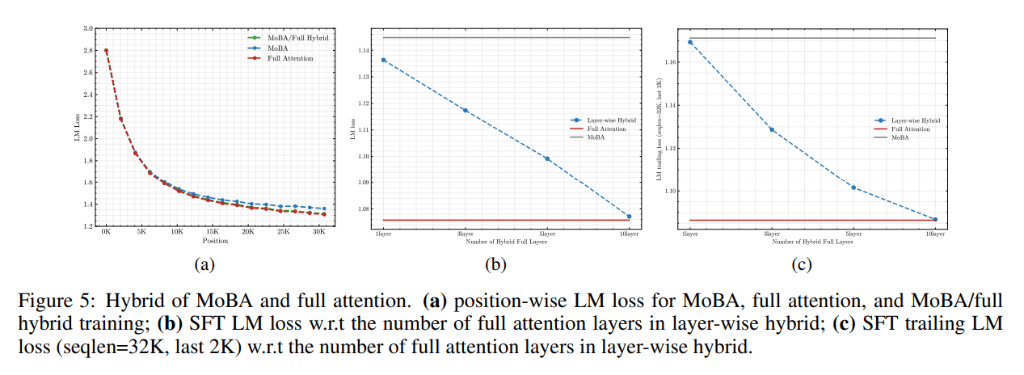
Kimi团队对MoBA进行了全面的实验验证,结果显示,尽管MoBA的注意力模式稀疏度高达81.25%,但其语言模型损失表现与全注意力相当。在长文本缩放能力实验中,通过增加序列长度到32K,MoBA的稀疏度进一步提高到95.31%,且性能与全注意力之间的差距逐渐缩小。更细粒度的块分割可以进一步提高MoBA的性能。
在混合训练实验中,Kimi团队发现,通过结合使用MoBA和全注意力进行训练,可以在训练效率和模型性能之间取得平衡。在多个真实世界的下游任务中,MoBA的表现与全注意力模型相当,甚至在某些任务上略有优势。
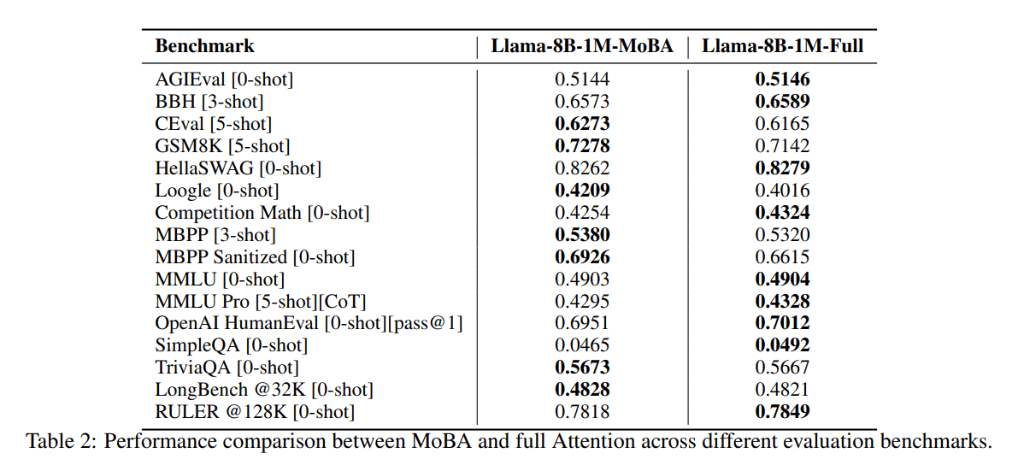
在处理效率和可扩展性方面,MoBA展现出了显著优势。实验表明,在处理长序列时,MoBA的计算复杂度为亚平方级,比全注意力更高效。特别是在处理1000万token的序列时,MoBA的注意力计算时间减少了16倍。
MoBA技术的推出,不仅标志着中国在稀疏注意力技术领域的重大突破,也为实现人工通用智能(AGI)提供了有力支持。随着技术的不断成熟和应用的不断拓展,MoBA有望在未来的人工智能领域发挥更加重要的作用。