在人工智能领域,一场围绕大模型技术的开源竞赛正愈演愈烈。就在DeepSeek发布其最新的稀疏注意力框架NSA论文后不久,另一支备受瞩目的大模型团队“月之暗面Kimi”也迅速跟进,公布了名为MoBA的论文,同样聚焦于提升大模型在处理超长序列任务时的效率和性能。
据悉,MoBA框架旨在通过实现高效、动态的注意力选择,来解决长文本处理中的效率难题。与NSA类似,MoBA也是一个稀疏注意力框架,但其最大上下文长度可扩展至惊人的10M,远超NSA的64k限制。这一突破性的进展,无疑为长文本处理任务提供了更为强大的工具。
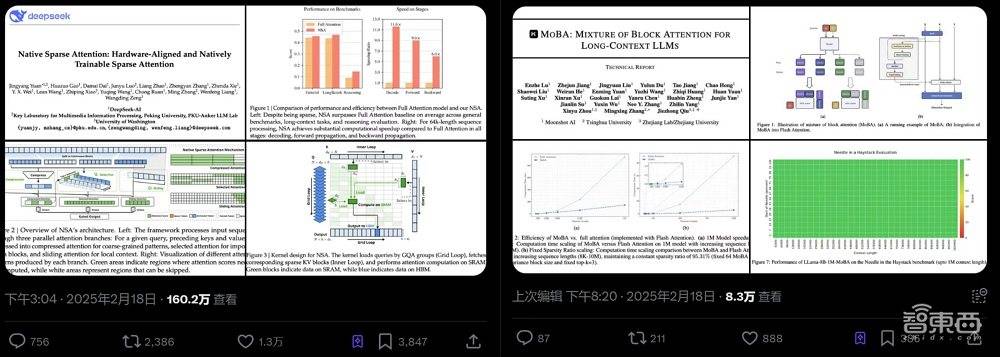
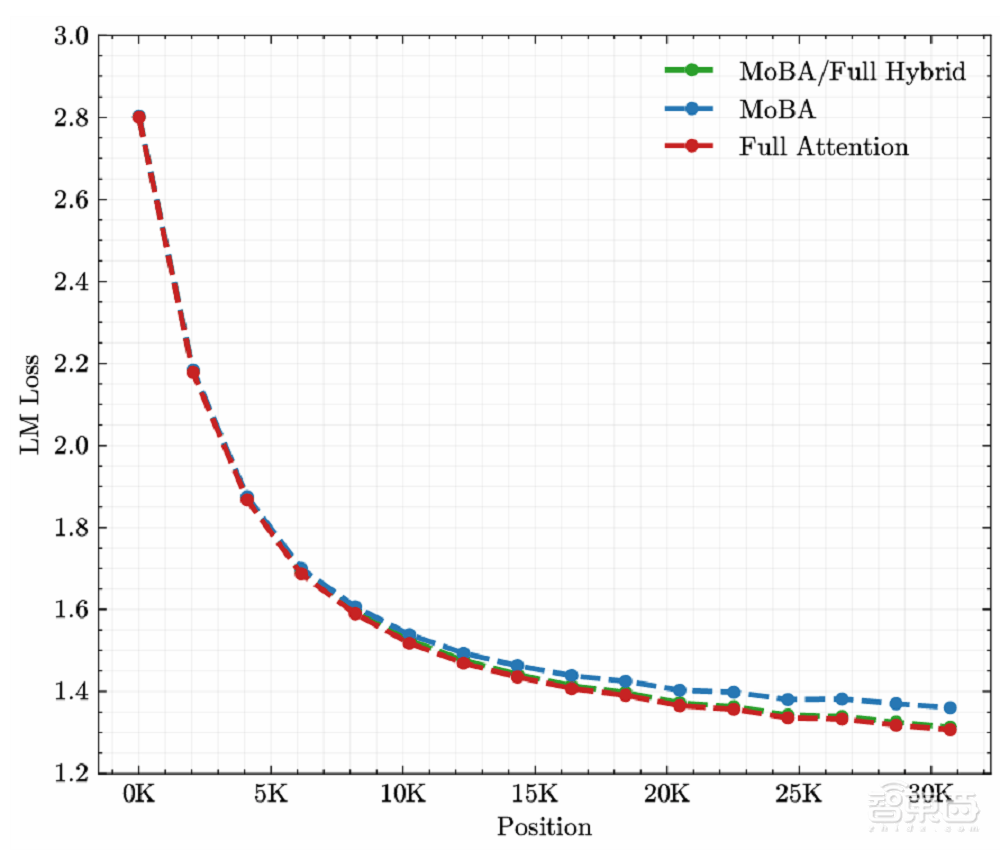
MoBA还借鉴了MoE中细粒度划分的思想,通过增加块的数量和减小块的大小,模型能够更精准地捕捉局部信息,同时减少不必要的计算。这一设计使得MoBA能够在保持与全注意力机制相当效果的同时,显著提升计算效率。
实验结果表明,MoBA在处理长达100万tokens的序列时,其速度比全注意力架构快6.5倍;在扩展到1000万tokens时,与标准Flash Attention相比,MoBA的计算时间实现了16倍的加速比。这一显著的优势,使得MoBA在处理极长序列任务时具有极高的性价比。
MoBA框架还具备高度的灵活性和兼容性。它能够在全注意力和稀疏注意力模式之间无缝切换,从而最大化与现有预训练模型的兼容性。这一特性使得MoBA能够轻松融入现有的AI系统中,为开发者提供更为便捷和高效的解决方案。
除了MoBA框架的发布外,月之暗面团队还面向开发者推出了一款最新的模型——Kimi Latest。这款模型旨在弥合Kimi智能助手和开放平台之间模型的差异,为开发者提供更为稳定和高效的AI解决方案。Kimi Latest模型支持自动上下文缓存,缓存命中的Tokens费用仅为1元/百万tokens,大大降低了开发者的使用成本。
随着DeepSeek、月之暗面等国内大模型团队的纷纷开源和技术分享,一场围绕大模型技术的开源军备竞赛正愈演愈烈。这不仅有助于推动AI技术的快速发展和应用落地,也为开发者提供了更为丰富和多样的选择。在这场竞赛中,月之暗面团队凭借其创新的MoBA框架和Kimi Latest模型,无疑成为了备受瞩目的焦点之一。