在AI领域的激烈竞争中,两款应用“豆包”与“DeepSeek”的故事,如同一出跌宕起伏的戏剧,吸引了业界的广泛关注。
“豆包”自诞生之日起,便被视为含着金钥匙的贵族。依托字节跳动强大的资源、人力和流量支持,它迅速成长为2024年国内用户量庞大的AI应用。按照既定的发展蓝图,豆包的目标是在今年实现2至3亿的月活跃用户数(MAU),剑指去年ChatGPT所达到的用户规模。然而,这一雄心勃勃的计划却被一匹突如其来的黑马——DeepSeek所打乱。
春节期间,DeepSeek凭借高涨的科技热潮,短暂地成为了国民级应用。据QuestMobile数据显示,1月28日,DeepSeek的日活跃用户数首次超越了豆包。在随后的七天内,它狂揽1亿用户,其增长速度甚至超过了ChatGPT,创造了互联网产品史上用户增长最快的纪录。央视财经也报道指出,DeepSeek的访问使用量急剧上升,迅速突破了3000万日活跃用户的大关。
值得注意的是,DeepSeek的爆发完全依赖于自然增长,官方并未进行任何投放或营销活动。相比之下,豆包则通过大规模的投放策略,在市场上运行了近半年时间。原本在C端AI应用市场上占据优势的豆包,如今面临了新的挑战者,这一切的发生令人始料未及。
DeepSeek的出现如同一条搅动市场的鲶鱼,为即将固化的市场格局带来了松动。从某种程度上看,字节跳动与DeepSeek的母公司深度求索在AI领域有着相似的追求和执念。然而,结果却是截然不同的。字节跳动似乎仍深陷于绩效主义的漩涡之中,而深度求索则成功跳出了大厂的射程范围。
深度求索一直专注于探索研究,目标直指通用人工智能(AGI)。在国内,标榜自己为AGI布道者的企业不在少数,这也一度吸引了投资者的关注。为了防御竞争,大厂们采取了多元化的策略,将资源分散到不同的领域。而其他入场玩家则迫于生存和融资的压力,不得不将精力集中在应用、To B等方向上。深度求索则显得与众不同,它始终致力于在底层通用大模型能力上取得突破。
据光子星球了解,在DeepSeek-R1诞生之前,除了部分大厂外,大部分AI创业公司已经放弃了模型训练。基础模型训练如同一个无底洞,投入大量资金却难以看到显著的提升。国内大模型的真相或许更多地体现在“套壳”和“粉饰”上。某知情人士透露,某AI企业在去年年初才开始自主训练大模型,但这并未影响它追赶GPT-o1的热潮。
在基础大模型之外,AI应用大致可以分为To B和To C两大派别。去年,C端AI应用市场竞争激烈,以豆包和月之暗面Kimi为代表的选手展开了激烈的获客营销大战。初期,大厂和创业公司纷纷下场,互不相让。然而,随着用户量和日活的拉开,竞争梯队逐渐形成,强劲的选手仅剩下豆包、Kimi和文小言等少数几个。
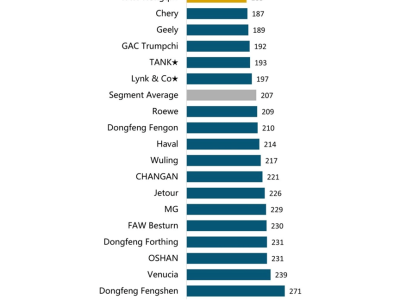
尽管投放策略备受争议,但在功能和产品体验未能拉开明显差距的前提下,豆包和Kimi还是选择了用资金换取用户增长。这无形中形成了一种潜规则:投放力度与用户活跃度成正比。AI产品榜数据显示,截至去年12月份,豆包的月活达到了7116万,而Kimi的月活为1669万。
然而,DeepSeek的横空出世打破了这一逻辑。它凭借一次智能升级驱动了产品升级,在推理模型的加持下,生成效果与同期竞品有了显著提升。它脱离了爬虫和网页检索逻辑,真正完成了“拆解-思考-推理-生成”的闭环。这就是DeepSeek在连续出现“服务器繁忙”提示的情况下,仍有大批用户愿意等待的原因。它还提供了市场上稀缺的用户价值。
在没有投放的前提下,DeepSeek仅上线一个月日活就超过了3000万,这是豆包经过一年疯狂推广都未曾达到的成绩。没有过多的优化、UI设计和功能聚合,仅仅是升级新模型能力后顺便上线的一款应用,却取得了意想不到的效果。这至少证明了在AI时代,投放获客逻辑并非万能。一款能满足用户需求的AI产品,仍然能够实现逆袭。
对于AI应用这道考题,深度求索和字节跳动从一开始就出现了分歧。对深度求索而言,这是一道可选题;而对字节跳动来说,则是一道必选题。面对汹涌而来的流量,深度求索有两种选择:一种是借着这股东风,向C端方向转型;另一种是保持最小投入,将应用产品作为大模型突破的副产品和展示窗口。从目前来看,深度求索对流量表现出了谨慎和放弃的态度。
在流量巅峰时期,它主动进行了锁区操作,禁止海外非中国用户注册和使用。面对服务器资源紧张的情况,也没有选择扩容,而是暂停了API服务充值。现在打开应用,深度推理功能使用次数超过三次以上时,显示服务器繁忙已成为常态。接近DeepSeek的人士透露,深度求索的目标感一直很强,对做一款应用没有太大兴趣,未来的方向可能仍然是在大模型和开源上。
相比之下,豆包的情况则大不相同。字节跳动本身就是C端属性很强的公司,豆包作为Flow部门主推的应用产品,前期投入已经巨大。再加上投放和指标压力,沉没成本显而易见。与DeepSeek不同,字节跳动拥有火山引擎云和Agent平台,无需靠豆包来证明模型能力。传统的搜索引擎正在被抛弃,AI搜索和Agent未来将逐步取而代之。字节跳动等大厂都在试图创造新的流量入口,豆包现在更像是各类AI功能的集合体。
一方面,它梳理了各类零散的AI应用;另一方面,也在为打通软硬件、内外部体系做准备。未来的理想状态是,用户只需要一个对话框就能唤起功能、实现需求。在上个时代,搜索引擎如百度、谷歌掌握了话语权;而现在,一切尚未可知。流量如同潮汐一般涨落是常态,DeepSeek的这波热潮亦是如此。
坦白来说,DeepSeek现在的用户体验并不是很好,与成熟的豆包仍有一定差距。DeepSeek所赋予的推理能力优势是暂时的,在开源和公开技术报告的背景下,字节跳动的产品化能力依然能发挥作用,追平只是时间问题。DeepSeek的爆火或许提供了新的思考时机,比如投放与用户之间的关系、模型能力与用户之间的关系以及产品体验与模型能力优化的平衡等等。
在字节跳动刚结束的全员会上,反思已经开始。据晚点报道,字节跳动CEO梁汝波提出,2025年将不再把豆包的日活跃用户数(DAU)作为具体目标,而是将重点放在追求“智能”上限上。他强调,不忽略关键技术节点,把智能本身作为最重要的目标,可以激发更多尝试。
从企业文化维度审视字节跳动和DeepSeek,它们如同一枚硬币的正反两面。面对充满不确定性的AI道路,两家公司都抱有同样的决心和不计成本、完全投入的心态。然而,在追求“大力出奇迹”的过程中,两者却呈现出截然不同的面貌。
在媒体报道中,有一个细节引人关注。深度求索的创始人梁文锋和张一鸣在招聘时,会主动接触尚在高校的研究生和博士生,并与其一起探讨论文研究中的细节。在候选人标准上,梁文锋坚持“看能力,而不是看经验”,核心技术岗位基本以应届和毕业一两年的人为主。当被问及大模型找人的必要条件时,梁文锋给出的回答是“热爱和扎实的基础能力”。
据说,DeepSeek内部有一个不成文的用人规则:工作经验超过8年者直接淘汰;超过5年者需要特别出色才能入选。而字节跳动则热衷于花大价钱挖掘行业中的高端人才。去年,字节跳动连续出手,将谷歌原VideoPoet项目负责人蒋路、零一万物黄文灏和阿里通义大模型原技术负责人周畅等纳入麾下。
一位曾在大厂体系内任职的人员透露,大厂的机制最终阻碍了创新。字节跳动等大模型团队背负着OKR指标,评判大模型效果的依据不是其性能或推理效果,而是能为多少个内部产品赋能以及产生多少用户量。AGI的远大梦想在实际落地中显得不堪一击,这导致很多时候越努力越偏离航向。
深度求索则通过顶会论文数量、获奖级别、竞赛级别等近乎苛刻的标准来筛选人才。虽然团队规模不大,但保证了人才质量。相比之下,高端人才的华丽履历成为了漂浮在大厂上方的光环。上述人员表示,大厂在大模型上的投入可能比不上创业团队。大厂动辄上百号人看似数量庞大,但分散到具体产品和业务条线后错综复杂。由于业务分支过多,聚焦到某个核心环节可能只有十几号人,在这个维度上,大厂的投入反而是不足的。