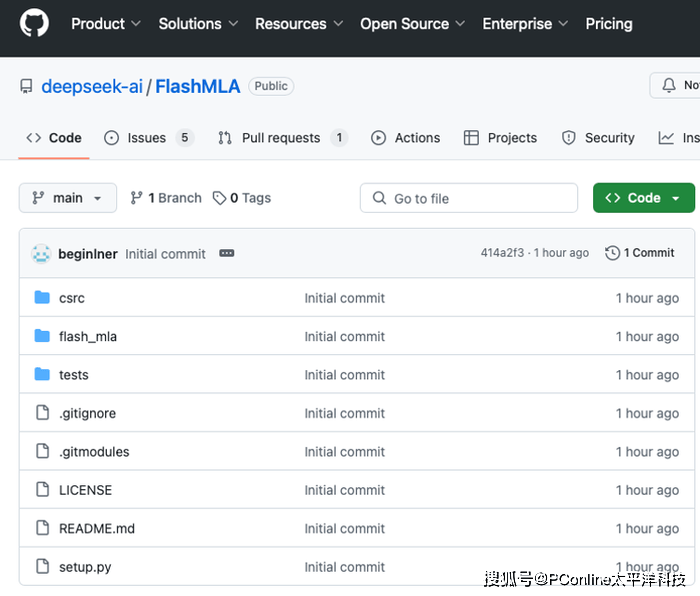
国内人工智能领域的领军者DeepSeek正式拉开了其开源周的序幕,而今日发布的FlashMLA项目无疑在AI技术界掀起了轩然大波。这一专为英伟达Hopper架构GPU量身打造的高效解码内核,不仅将H800 GPU的性能推向了新的巅峰,更是被誉为大模型推理服务的突破性加速器。
FlashMLA的核心优势在于其针对大语言模型(LLM)解码过程的深度优化。通过巧妙地重构内存访问和计算流程,它显著提升了变长序列处理的效率。这一设计的灵感虽然源自业界知名的FlashAttention 2&3和cutlass项目,但FlashMLA在分块调度和内存管理上实现了更为卓越的突破。
更令人瞩目的是,FlashMLA还拥有两大性能绝技。其一是分页KV缓存技术,采用页式内存管理策略,有效减少了显存碎片化问题,使得H800上的内存带宽飙升至惊人的3000 GB/s,特别适用于高并发推理场景。其二是BF16精度支持,这一特性在计算密集型任务中实现了精度与速度的完美平衡,单卡算力高达580 TFLOPS,相较于传统方案,性能提升超过30%。
DeepSeek官方透露,FlashMLA已经成功应用于实际生产环境,能够支持从聊天机器人到长文本生成的各类实时任务,为AI应用的商业化落地提供了即插即用的解决方案。这一成果不仅彰显了DeepSeek的技术实力,也预示着AI技术在实际应用中的巨大潜力。
在开源周的预热阶段,网友们纷纷猜测DeepSeek接下来的开源项目。有人甚至大胆预测,开源周的第五天或许会揭晓AGI(通用人工智能)的神秘面纱。这一推测背后,折射出DeepSeek构建“模型-开发者-软硬件”一体化生态的雄心壮志。通过开源降低技术门槛,吸引更多开发者参与,同时推动技术方案的标准化和商业化应用,DeepSeek正逐步抢占AI领域的制高点。

值得注意的是,FlashMLA的发布不仅标志着DeepSeek在AI技术上的重大突破,也揭示了整个AI行业的两大发展趋势。一方面,软硬件协同优化成为提升AI性能的关键路径。FlashMLA的成功实践表明,“特供”芯片与高效解码内核的结合能够释放出巨大的算力潜能。另一方面,开源成为推动AI技术普及和应用的重要力量。通过开源扩大影响力,吸引更多开发者参与,共同推动AI技术的标准化和商业化进程。

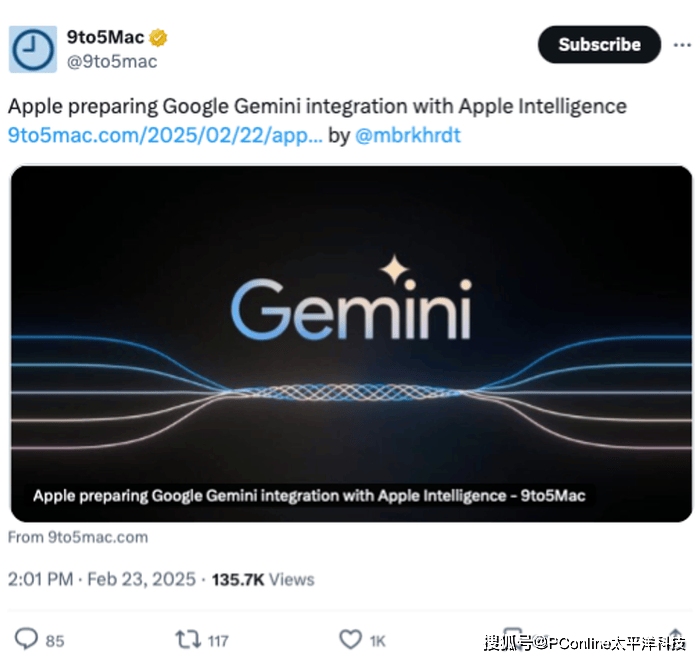
与此同时,AI领域的竞争也日益激烈。苹果与Google Gemini的合作宣布,进一步加剧了AI基座之争。在这个充满机遇与挑战的时代,DeepSeek通过开源周的一系列重磅项目,不仅展示了自身在AI技术上的深厚积累,也向业界传递了一个明确的信号:在通往通用人工智能的道路上,中国方案正加速前行。