在科技界风起云涌的浪潮中,一项新兴的研究成果犹如一股清流,迅速吸引了业界的广泛关注。近日,DeepSeek研究团队携其最新力作——一种名为NSA的全新注意力机制,强势回归,与马斯克发布的Grok 3形成了鲜明的对比,两者热度不相上下。
DeepSeek团队通过一条简短的推文,便引发了超过三十万次的浏览热潮,其影响力直逼OpenAI。推文中透露出的研究论文,更是如同一枚重磅炸弹,震撼了整个AI领域。
NSA,这一由DeepSeek团队精心打造的注意力机制,以其独特的动态分层稀疏策略、粗粒度token压缩以及细粒度token选择三大核心技术,成功实现了在大幅降低预训练成本的同时,显著提升推理速度。特别是在解码阶段,其性能提升高达11.6倍,令人叹为观止。
DeepSeek的创始人兼CEO梁文锋,此次不仅亲自参与了研究,更是亲自提交了论文,这无疑为团队的研究成果增添了更多的分量。他的身影出现在合著名单之中,也引发了网友们的纷纷调侃,甚至有人借此机会向奥特曼“示好”,戏称DeepSeek又发表了一篇强大的新论文。
NSA的问世,无疑填补了稀疏注意力机制存在的缺陷。随着AI技术的不断发展,长上下文建模能力的重要性日益凸显。然而,传统的注意力机制在面对越来越长的序列时,其复杂性成为了制约运行速度的瓶颈。NSA通过巧妙地利用softmax注意力的固有稀疏性,选择性地计算关键的query-key对,从而实现了计算开销的大幅降低,同时保持了模型的卓越性能。
DeepSeek团队在研究中发现,现有的稀疏注意力技术在实际部署时往往未能达到预期效果,且大多集中在推理阶段,缺乏对训练阶段的有效支持。为此,他们提出了原生可训练的稀疏注意力架构NSA,通过动态分层稀疏策略、粗粒度token压缩和细粒度token选择的有机结合,成功保留了全局上下文感知能力和局部精确性。
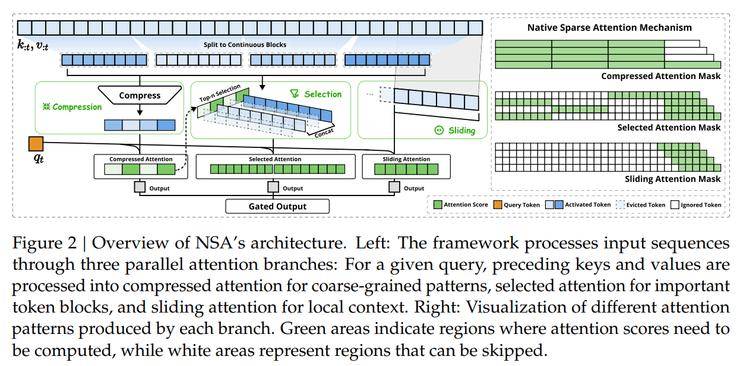
在评估NSA的技术性能时,研究团队从通用基准性能、长文本基准性能和思维链推理性能三个维度进行了全面比较。结果显示,NSA在各项评测中均表现出色,不仅预训练损失曲线稳定平滑,且整体性能优于全注意力模型和现有的稀疏注意力方法。
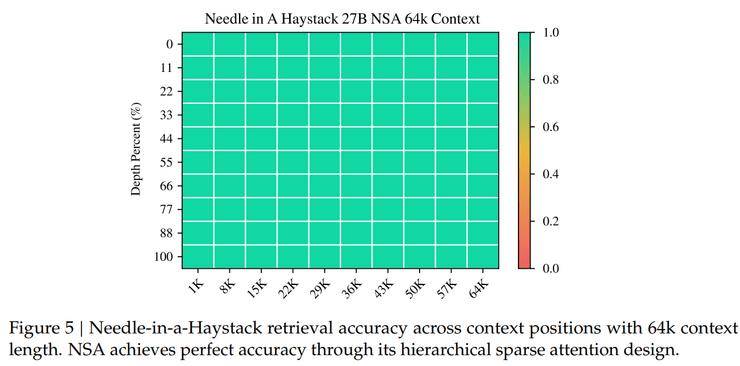
特别是在长上下文任务中,NSA展现出了极高的检索精度和全局感知能力。这得益于其分层稀疏注意力设计,通过粗粒度token压缩实现了高效的全局上下文扫描,同时通过细粒度选择性标记保留了关键信息,从而实现了全局感知与局部精确度的完美平衡。
NSA还通过Triton开发了与硬件高度兼容的稀疏注意力内核,进一步优化了计算效率。DeepSeek团队采用的查询分组方法,通过组内数据加载、共享KV加载和网格循环调度等特性,实现了接近最优的计算强度平衡。
NSA的研究成果还验证了清华大学姚班早期论文中的结论。在处理复杂数学问题时,NSA通过优化问题理解和答案生成,成功减少了所需的tokens数量,从而得出了正确答案。这一显著提升不仅展示了NSA在效率和准确性上的优势,也再次证明了AI技术在不断推陈出新中取得的长足进步。