近日,清华大学携手瑞莱智慧公司,共同发布了一款名为RealSafe-R1的大语言模型。该模型是对DeepSeek R1的深度优化与强化训练成果,不仅保持了卓越的性能稳定性,更在安全性方面实现了质的飞跃,超越了诸如Claude3.5和GPT-4o等被广泛认为安全性较高的闭源大模型,为开源大模型的安全发展提供了创新性的路径。
DeepSeek作为国产开源大模型的佼佼者,其在自然语言处理和多任务推理领域展现出的强大实力令人瞩目,尤其在处理复杂问题和创造性任务时更是表现出色。然而,即便是如此优秀的模型,在面对如越狱攻击等安全挑战时,也暴露出了局限性。恶意设计的输入可能会误导模型,导致生成不安全或不符合预期的响应。这一安全问题并非DeepSeek独有,而是开源大模型普遍面临的难题,根源在于安全对齐机制的不足。
针对这一问题,清华大学与瑞莱智慧的联合团队提出了创新的解决方案——基于模型自我提升的安全对齐方式。这一方法将安全对齐与内省推理相结合,使大语言模型能够通过具备安全意识的思维链分析,自主识别并规避潜在风险,从而实现模型自身能力的进化。该方案不仅适用于DeepSeek系列模型,还可广泛应用于其他开源或闭源模型。
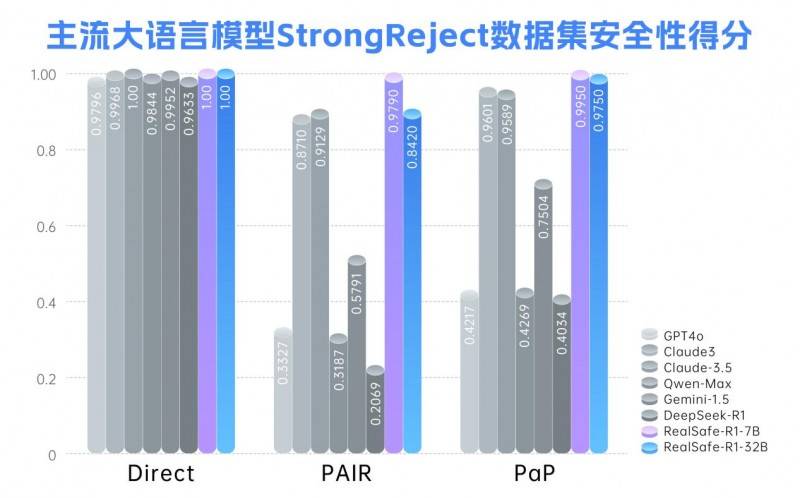
基于上述创新方法,团队对DeepSeek-R1系列模型进行了后训练,成功推出了RealSafe-R1系列大模型。实验数据表明,RealSafe-R1在安全性方面取得了显著提升,有效增强了模型对各种越狱攻击的抵抗力,同时减轻了安全与性能之间的冲突,整体表现优于Claude3.5和GPT-4o等闭源大模型。这一成果不仅丰富了DeepSeek生态,更为大语言模型的安全发展树立了新的标杆。
瑞莱智慧首席执行官田天表示:“大模型的安全性瓶颈是制约人工智能产业高质量发展的关键因素。只有通过持续投入和创新,补齐安全短板,我们才能为政务、金融、医疗等严肃场景的应用提供更为可靠的坚实基座。”据悉,RealSafe-R1各尺寸模型及数据集将于近期向全球开发者开放,这将为开源大模型的安全性加固提供有力支持,进一步推动人工智能技术的广泛应用与发展。