DeepSeek公司于近日宣布了一项重大进展,正式推出了DeepEP,这是一款专为混合专家(MoE)模型设计和打造的开源通信库。DeepEP的问世,标志着在MoE模型的训练和推理过程中,通信效率将得到显著提升。
据悉,DeepEP以其高效和优化的全员沟通能力为核心亮点之一。它不仅能够实现节点内部的顺畅通信,还支持节点间的NVLink和RDMA连接,为用户提供了更为多样和灵活的通信选项。这一特性对于提升大规模分布式训练的效率至关重要。
为了应对训练和推理过程中的不同需求,DeepEP内置了两种专门优化的内核。一方面,针对训练场景,它提供了预填充的高吞吐量内核,以确保数据处理的高速和稳定;另一方面,针对推理场景,它则配备了低延迟内核,旨在提升解码速度和响应效率。这样的设计使得DeepEP能够在不同的应用场景下都能发挥出最佳性能。
DeepEP还原生支持FP8调度,这一特性使得它能够在保持高精度的同时,进一步降低计算和通信的开销。同时,DeepEP还提供了灵活的GPU资源控制功能,用户可以根据实际需求灵活配置资源,并实现计算与通信的重叠,从而进一步提升整体性能。
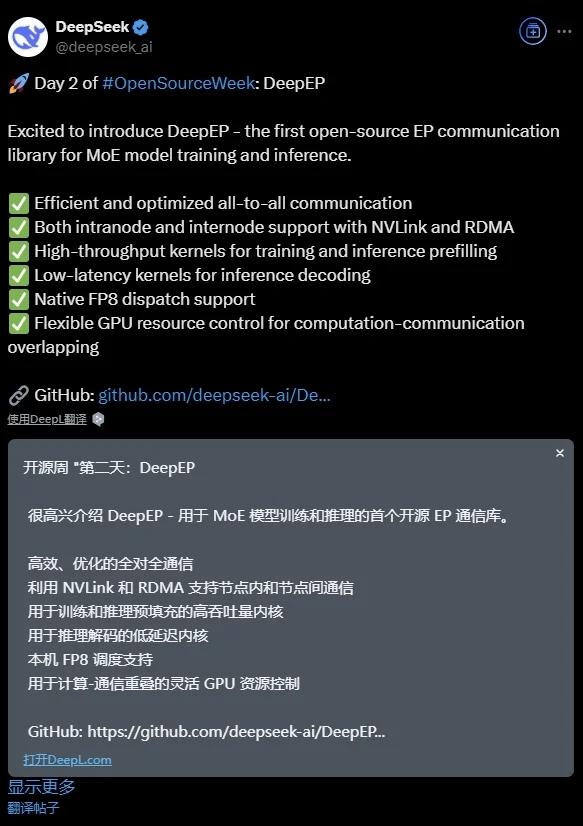
DeepEP的推出,无疑将为MoE模型的研究和应用带来新的突破。它以其高效、灵活和优化的通信能力,为用户提供了更为强大和可靠的支持。随着DeepEP的开源,相信将会有更多的开发者和研究者加入到这一领域中来,共同推动MoE模型技术的不断发展和进步。