金山云近期宣布,已经成功适配了阶跃星辰最新推出的两款多模态大模型,为用户带来了前所未有的体验。这两款模型分别是全球参数量最大的开源视频生成模型Step-Video-T2V,以及业界首款产品级开源语音交互模型Step-Audio。现在,用户只需登录金山云官方网站,即可轻松体验。
在Step-Video-T2V模型的适配上,金山云凭借强大的算力支持和稳定的运行环境,充分释放了模型的性能,为用户带来了流畅的视频生成体验。据了解,Step-Video-T2V模型拥有高达300亿的参数,能够直接生成204帧、540P分辨率的高质量视频。在各项评测中,该模型在指令遵循、运动平滑性、物理合理性以及美感度等方面,均显著超越了目前市面上效果最佳的开源视频生成模型。
为了支持Step-Video-T2V模型的多卡并行部署,阶跃星辰官方提供了全面的支持。其中,文本编码器和VAE部分由独立的进程维护,而DiT部分则可以选择4卡并行或8卡并行,每张卡至少需要80G的显存。对于单台机器的运行,推荐使用5个80G显存的GPU。在部署方面,金山云已经为用户预装好了ubuntu22.04系统,并内置了Step-Video-T2V模型和依赖环境的镜像。通过金山云的云计算环境,可以精准协调各卡资源,确保文本编码器、VAE和DiT等部分协同工作,大幅提升视频生成效率。
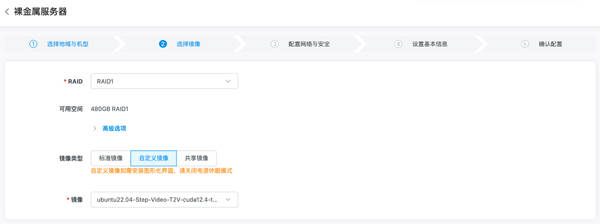
用户只需在金山云裸金属服务器控制台选择内置Step-Video-T2V的自定义镜像进行创建,创建完成后即可启动模型并使用。启动服务也非常简单,用户只需登录服务器进入Step-Video-T2V-main目录,运行相应的Python脚本即可。当看到“Running on all addresses (0.0.0.0)”的提示时,即表示服务已成功启动。
除了Step-Video-T2V模型外,金山云还完成了实时语音对话系统Step-Audio模型的适配工作。通过先进的云计算技术,金山云降低了模型的响应延迟,让用户与模型的对话更加自然流畅。无论是实时语音聊天还是语音指令控制,Step-Audio模型都能快速准确地响应,为用户提供优质的语音交互服务。Step-Audio作为业内创新性的开源语音模型,能够根据不同的场景需求生成情绪、方言、语种、歌声和个性化风格的表达,并与用户进行高质量对话。
在各项主流公开评测中,Step-Audio模型均表现出色,位列第一。特别是在HSK-6(汉语水平考试六级)评测中,Step-Audio模型更是展现出了卓越的性能,成为最懂中国话的开源语音交互大模型。
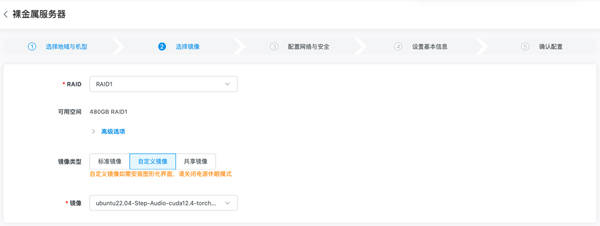
在部署方面,金山云同样为用户预装好了ubuntu22.04系统,并内置了Step-Audio模型和依赖环境的镜像。用户只需在金山云裸金属服务器控制台选择内置Step-Audio的自定义镜像进行创建,创建完成后即可启动模型并使用。启动服务同样简单,用户只需登录服务器进入Step-Audio-main目录,运行相应的Python脚本即可。
随着人工智能技术的快速发展,金山云始终与前沿技术保持同步,不断携手生态合作伙伴,为前沿技术的落地转化提供有力支持。通过此次对阶跃星辰两款多模态大模型的适配,金山云再次展现了其在云计算领域的强大实力和技术创新能力。