在信息安全领域,恶意软件为了规避安全分析人员的追踪,常常采用混淆技术来掩盖其真实目的和运行逻辑。这一做法给安全分析带来了巨大挑战,传统工具和分析方法往往力不从心,效率低下且缺乏普适性。然而,随着人工智能技术的飞速发展,特别是Transformer模型的兴起,为这一难题提供了新的解决方案。
Transformer模型最初应用于机器翻译领域,其后发展出的大型语言模型(LLM)已经能够胜任对话、推理等复杂任务。混淆技术的核心在于通过复杂化代码逻辑来阻碍人类分析者的理解过程,而LLM所具备的归纳和推理能力恰好能够应对这一挑战,为反混淆提供了新的思路。
传统去混淆方法主要分为静态分析和动态分析两类。以OLLVM为例,安全研究人员需要识别诸如控制流平坦化、指令替换、虚假控制流等混淆特征,并通过模拟执行或符号执行来还原原始代码逻辑。这种方法不仅工程量大,而且耗时费力,每种混淆工具都需要单独分析其特征。
相比之下,基于LLM的反混淆方法则显得更为高效和通用。通过将多种编程语言及其去混淆方法整合到一个统一的模型中,LLM能够自动识别和还原混淆代码。这一方法的基本流程包括两个步骤:首先,LLM通过大量数据训练学习混淆特征;其次,利用LLM的推理能力提取原始代码逻辑。这一过程不仅大大减轻了人工分析的负担,还提高了去混淆的准确性和效率。
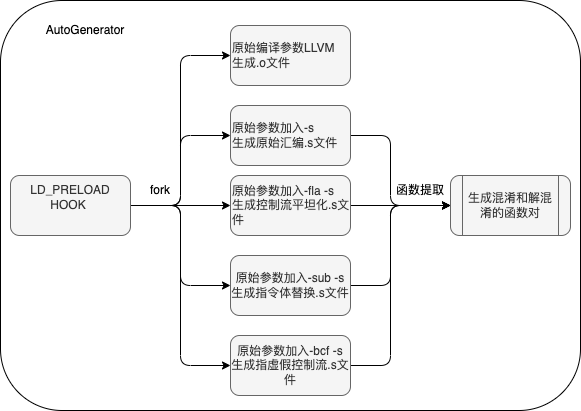
为了训练这一模型,研究人员开发了一个名为AutoGenerator的工具。该工具通过LD_PRELOAD技术注入到编译器中,提取编译参数并生成未混淆的代码以及多种混淆变体。这些代码被用作训练数据,用于微调LLM模型。经过大量数据的训练,模型在去混淆任务上取得了显著成效。
在实际应用中,研究人员对微调后的模型进行了初步测试。结果显示,模型在14组未训练的代码上去混淆的准确率高达90%以上,明显优于传统GPT模型的表现。这一成果不仅证明了LLM在去混淆领域的潜力,也为二进制安全研究提供了新的工具和方法。


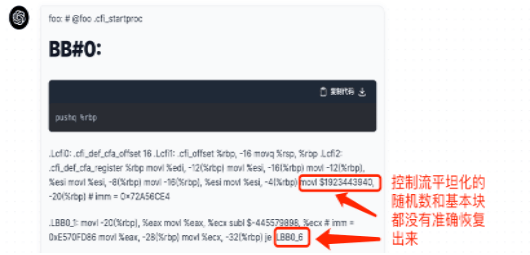

LLM在逆向工程领域也展现出巨大潜力。逆向工程需要从低级语言(如汇编)转换到高级语言(如C语言),这一过程中往往存在信息缺失的问题。而LLM在预训练阶段已经学习了大量知识,能够弥补这一信息缺失,提高逆向工程的准确性和效率。
随着大型语言模型技术的不断发展,其在信息安全领域的应用前景愈发广阔。未来,我们有望看到更多基于LLM的安全工具和方法涌现,为二进制安全研究和实践注入新的活力。