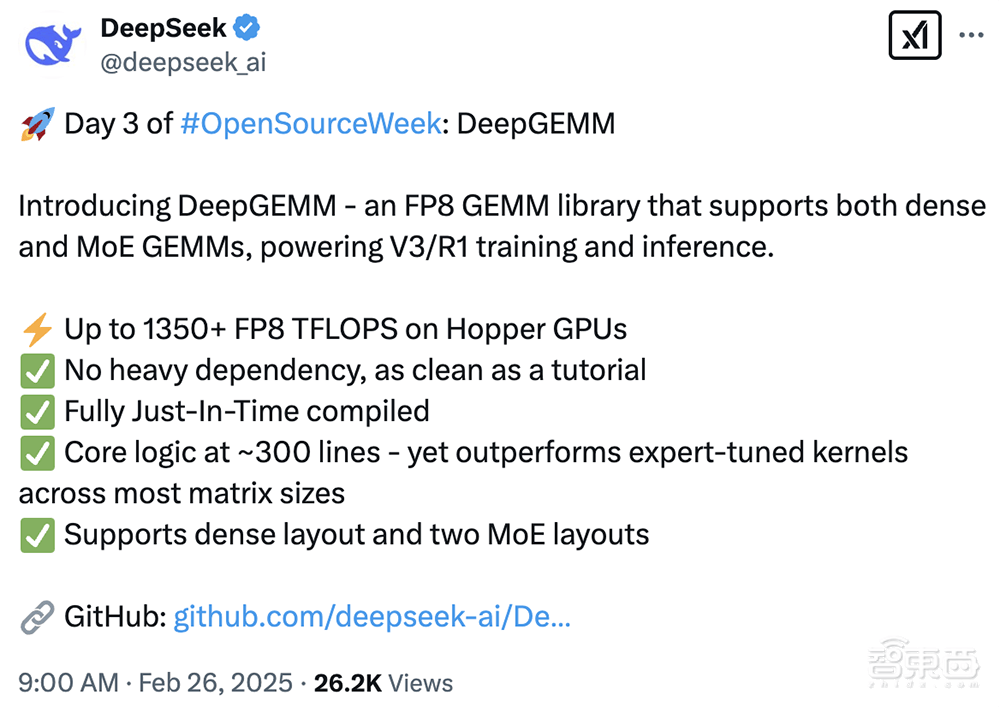
在深度学习领域,又迎来了一次技术革新。DeepSeek开源周的第三波发布——DeepGEMM,一个专为密集和混合专家(MoE)模型设计的FP8通用矩阵乘法(GEMM)库,正式亮相。这一创新成果,旨在为V3/R1的训练和推理提供强大动力。
DeepGEMM的发布引起了广泛关注,其性能在Hopper GPU上高达1350+ FP8 TFLOPS,且设计简洁,没有过多的依赖。据悉,该库在安装过程中无需预编译,而是采用完全即时(JIT)编译的方式,使得安装过程如教程般顺畅。其极简的设计理念,核心逻辑仅约300行代码,却能在大多数矩阵大小上超越专家调整的kernels,展现出卓越的性能。
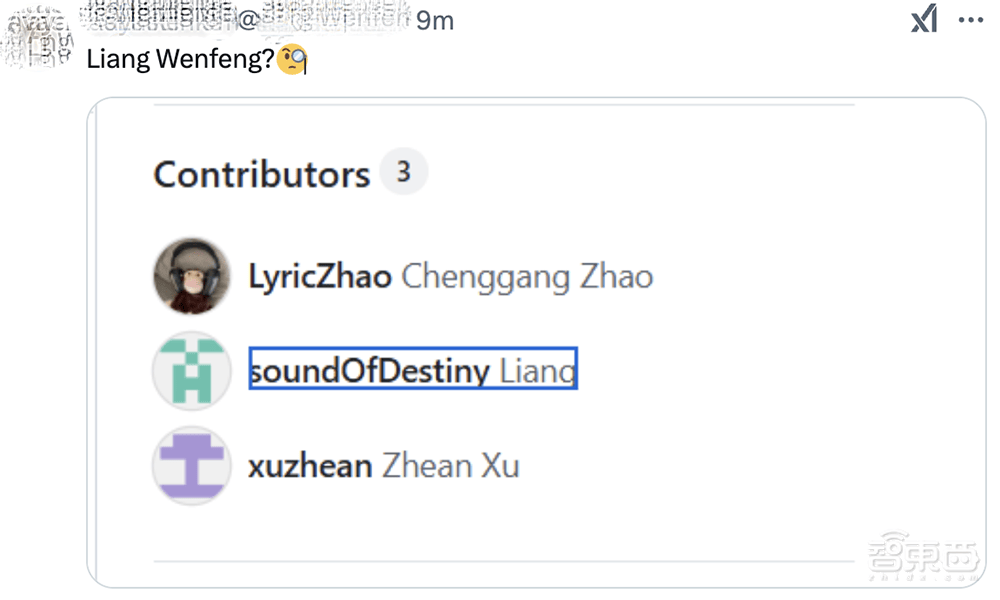
DeepGEMM不仅支持普通的密集布局,还兼容两种MoE布局,为不同类型的模型提供了全面的支持。这一特性使得DeepGEMM在深度学习领域具有广泛的应用前景。有眼尖的网友在项目贡献者名单中发现了“Liang”的名字,并猜测这可能是DeepSeek的创始人梁文锋。这一猜测在DeepSeek的推文评论区引发了热烈讨论。
据DeepSeek公布的数据显示,DeepGEMM在普通GEMM(密集模型)中,矩阵运算的提速可达2.7倍;在分组GEMM(MoE模型)中,连续性布局和掩码布局下的提速也能达到1.1倍至1.2倍。这一显著的性能提升,得益于DeepGEMM专为干净、高效的FP8 GEMM而设计的理念,以及细粒度扩展功能的实现。
DeepGEMM采用了CUDA核心两级累积技术,解决了不精确的FP8 Tensor Core累积问题。尽管它借鉴了CUTLASS和CuTe的一些概念,但避免了对其模板或代数的过度依赖,使得库的设计更加简洁明了。这一特性也使得DeepGEMM成为学习Hopper FP8矩阵乘法和优化技术的宝贵资源。
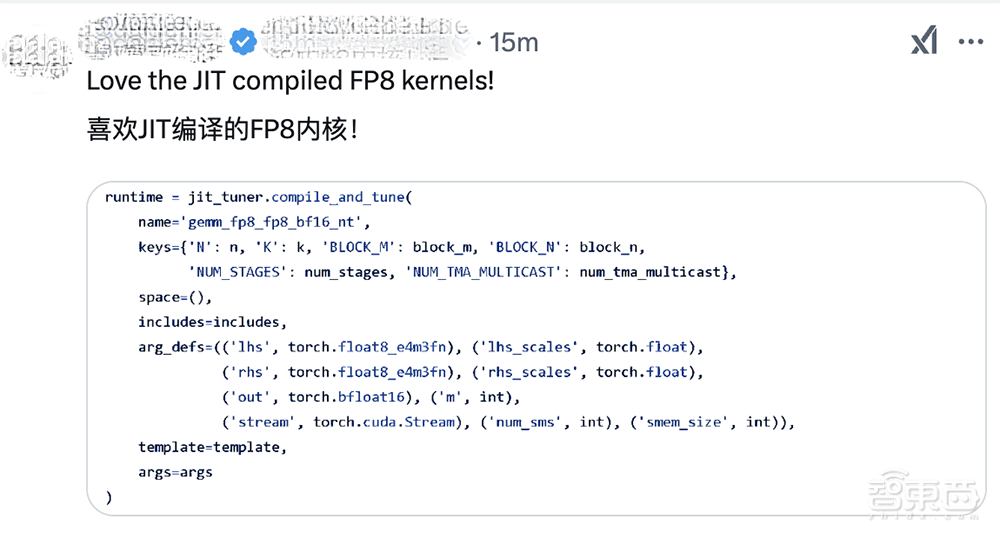
DeepGEMM的发布,在DeepSeek的推文评论区收获了众多好评。网友们纷纷夸赞新代码库的出色性能和DeepSeek工程师的辛勤付出。DeepSeek也分享了清晰的上手指南,帮助开发者快速上手DeepGEMM。该指南要求使用Hopper架构的GPU,支持sm_90a,以及Python 3.8、CUDA 12.3、PyTorch 2.1等环境配置。DeepSeek强烈推荐使用CUDA 12.8或更高版本以获得最佳性能。
DeepGEMM的代码库不仅包含了GEMM kernel,还提供了一些实用函数和环境变量,方便开发者进行二次开发和优化。DeepSeek还详细解释了DeepGEMM的设计原理和优化细节,如利用Hopper TMA功能实现更快的数据移动、针对不同warpgroups定制的寄存器计数控制等。这些优化措施共同提升了DeepGEMM的性能,使其在深度学习领域具有更强的竞争力。