在科技界的万众瞩目下,DeepSeek开源周的精彩继续上演,此次推出的高性能矩阵计算库DeepGEMM,无疑成为了众人瞩目的焦点。这款被誉为“AI数学加速器”的开源工具,旨在为大模型训练和推理提供前所未有的速度提升。
DeepGEMM在Hopper架构的GPU上实现了惊人的FP8精度下1350+ TFLOPS的算力表现。这一数字远超当前市面上的主流显卡,如RTX 4090的400-500 TFLOPS,展现了其卓越的性能优势。FP8精度,即8位浮点数格式,通过牺牲微小的精度换取了3倍以上的速度提升,这一策略在AI场景中尤为适用,因为AI应用通常对误差具有一定的容忍性。
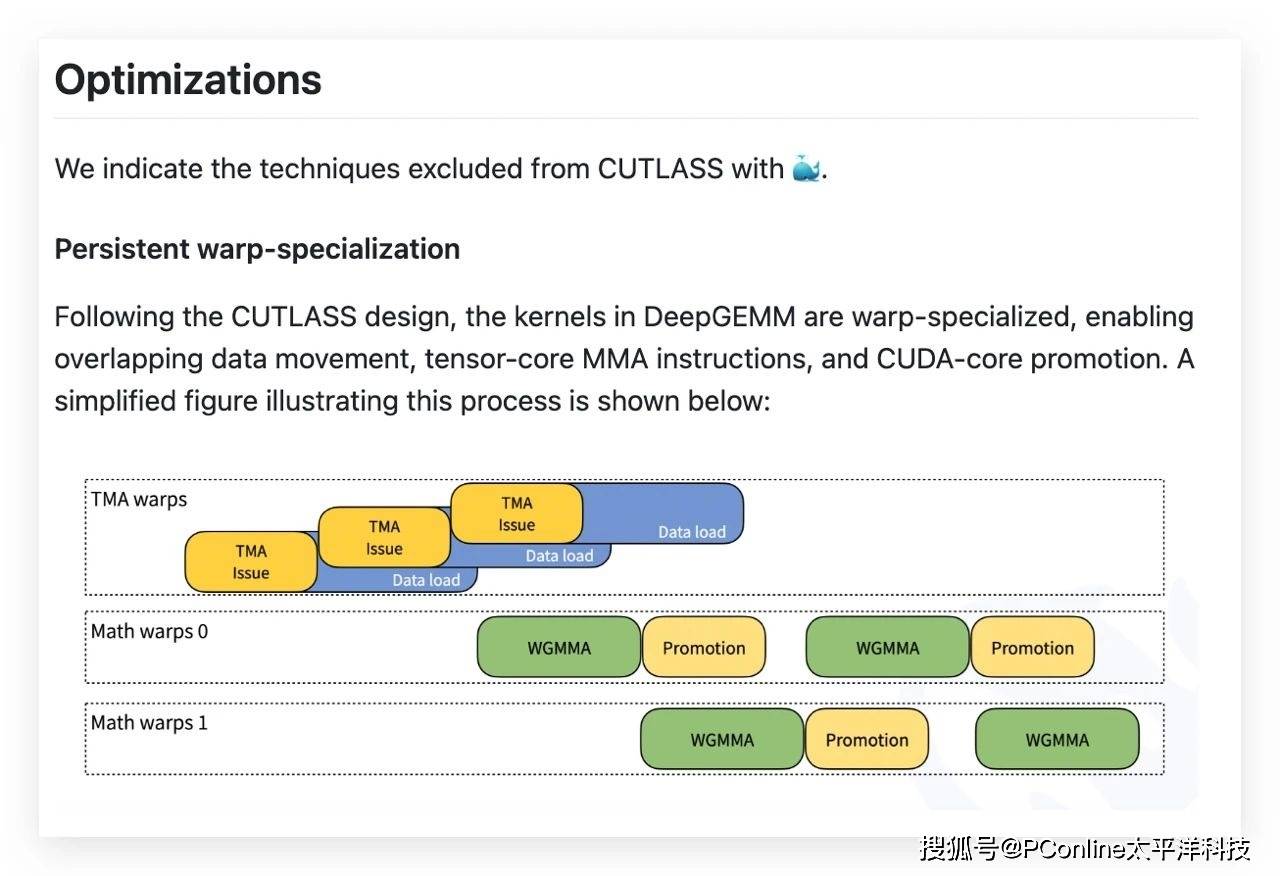
更令人惊叹的是,DeepGEMM的核心逻辑仅用300行代码实现,却通过全流程JIT编译优化,达到了比手工调优算子更高的效能。这一极简代码哲学,不仅摒弃了冗余设计,还专注于底层优化,重新定义了高性能计算的边界。开发者可以轻松地将DeepGEMM集成到现有框架中,无需额外的依赖项。
DeepGEMM还支持双模式,即稠密矩阵布局和混合MoE布局,以适应不同模型的需求。稠密矩阵布局适用于全量数据的统一计算,而混合MoE布局则能够分任务处理,提高了计算的灵活性。

在FP8精度下,DeepGEMM还展现出了“省电模式”的优势。低精度计算大幅降低了显存占用和功耗,使得万亿参数的大模型在24G显存的单卡上也能实现28倍的推理加速。这一特性在KTransformers项目中得到了验证。
DeepGEMM在MoE模型上进行了杀手级优化。通过连续/掩码双布局,解决了专家模型计算中的通信瓶颈,使得万亿参数的MoE推理速度如闪电般迅速。这一优化不仅提升了性能,还进一步降低了计算成本。
DeepGEMM的开源,预示着DeepSeek在算力领域的又一次重大突破。据悉,DeepSeek正在加速推出其R1模型的升级版——DeepSeek R2,预计将在5月发布。这一升级版将借助DeepGEMM的强大算力,进一步提升模型训练和推理的速度。

与此同时,DeepSeek也重新开放了API充值入口。此前,由于资源紧张,该入口一度关闭。目前,deepseek-chat模型的优惠期已经结束,调用价格已调整为每百万输入tokens 2元,每百万输出tokens 8元。这一调整旨在更好地满足用户的需求,同时也为DeepSeek的持续发展提供了资金支持。