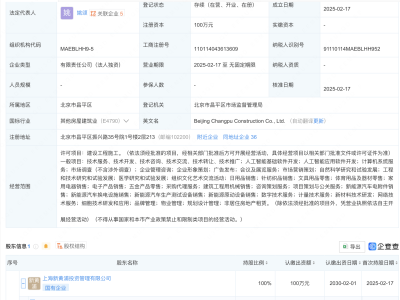
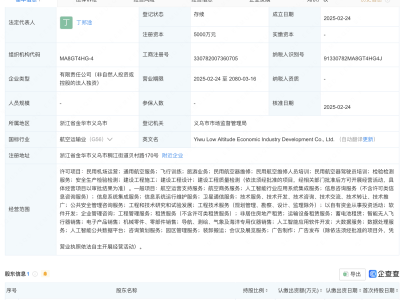
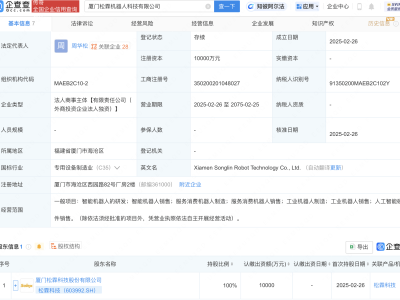
在人工智能领域的一次重大开源行动中,DeepSeek项目在近期的一次活动中,一次性向公众开放了三个重要的代码库,这一举措在业界引起了广泛关注。
这三个代码库分别是DualPipe、EPLB以及profile-data。DualPipe是一种创新的双向流水线并行算法,旨在通过计算和通信的重叠来减少深度学习模型训练过程中的空闲时间。EPLB则是一个专家并行负载均衡器,用于优化不同GPU之间的工作负载分配,确保资源的高效利用。而profile-data则提供了对DeepSeek训练和推理框架的分析数据,帮助开发者更好地理解和优化他们的模型。

据DeepSeek团队介绍,DualPipe算法通过实现前向和后向计算通信阶段的完全重叠,有效减少了流水线气泡,提高了训练效率。而EPLB负载均衡器则通过采用冗余专家策略和组限制专家路由,确保了不同GPU之间的负载均衡,减少了节点间的数据流量。
DeepSeek的这一开源行动得到了业界的广泛赞誉。许多开发者在评论区表示,DeepSeek的项目团队展现出了卓越的团队合作能力,他们的开源精神为整个行业树立了榜样。有开发者甚至称赞DeepSeek的这一举措“打开了最后的封印”,为深度学习领域的发展注入了新的活力。

DualPipe算法的具体实现中,DeepSeek团队采用了8个PP列和20个微批的调度策略,实现了前向和后向块的计算和通信的重叠。通过比较流水线气泡和内存使用情况,他们发现DualPipe算法能够显著提高训练效率,减少资源浪费。
EPLB负载均衡器则提供了分层负载平衡和全局负载平衡两种策略,以适应不同的情况。在分层负载平衡策略中,DeepSeek团队首先将专家组均匀打包到节点上,确保不同节点的负载均衡。然后在每个节点内复制专家,最后将复制的专家打包到各个GPU,以确保不同的GPU负载平衡。而在全局负载平衡策略中,他们则在全局范围内复制专家,并将复制的专家打包到单个GPU,以适应专家并行度较大的解码阶段。
最后,profile-data代码库为开发者提供了对DeepSeek训练和推理框架的深入分析数据。通过使用PyTorch Profiler捕获分析数据,开发者可以直观地了解他们的模型在训练和推理过程中的性能表现,从而进行有针对性的优化。
DeepSeek的这一开源行动不仅为开发者提供了宝贵的资源和工具,也展示了他们在深度学习领域的深厚实力和创新精神。随着这些代码库的广泛应用和不断优化,我们有理由相信,深度学习领域将迎来更加繁荣和高效的发展。