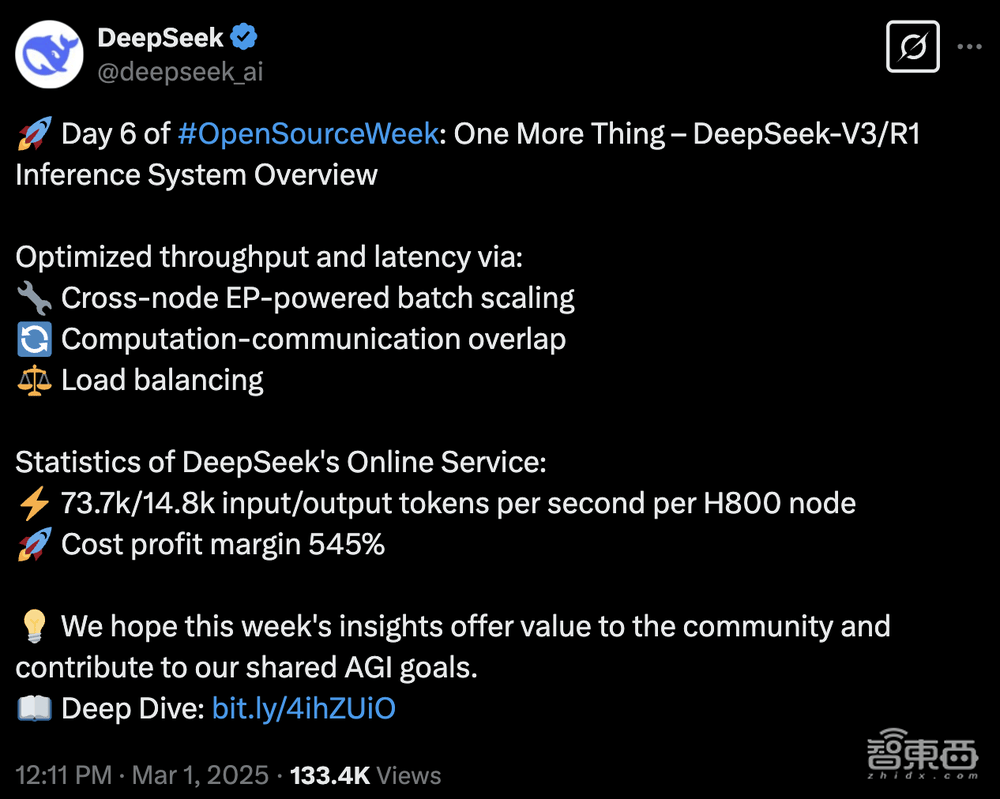
在AI开源领域,DeepSeek的开源周活动不仅吸引了大量开发者关注,还意外地带来了一个令人瞩目的财务透明度展示。近日,DeepSeek在开源活动的第六天,不仅分享了其最新的DeepSeek-V3/R1推理系统技术细节,还罕见地公开了系统的每日成本和理论收入情况,这一举动迅速引起了业界的广泛讨论。
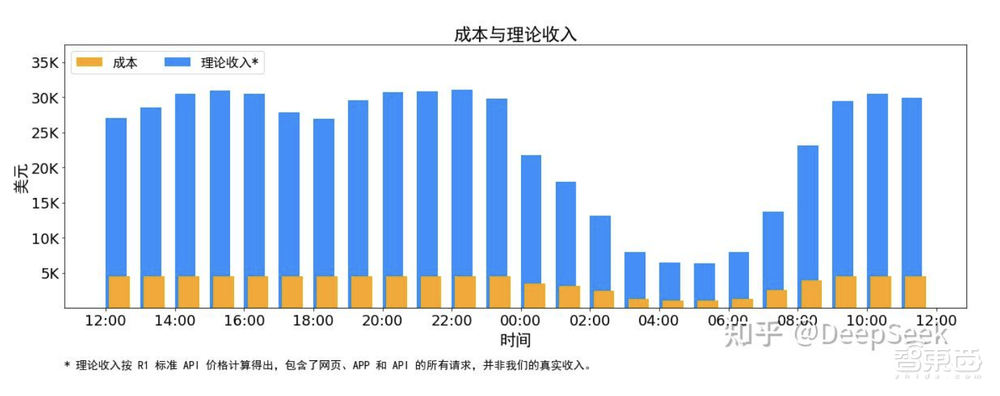
据DeepSeek公布的数据显示,从2月27日24时至2月28日24时,其每日总成本达到了87072美元(约合人民币63万元)。而如果以DeepSeek-R1的定价来计算,其每日理论总收入将高达562027美元(约合人民币409万元),成本利润率惊人地达到了545%,意味着DeepSeek理论上每天可以净赚474955美元(约合人民币346万元)。
然而,实际情况远比理论数据复杂。DeepSeek-V3的定价低于R1,且网页端和应用程序的服务是免费的,只有部分服务产生收入。非高峰时段还提供夜间折扣,这些因素都导致了DeepSeek的实际收入远低于理论值。
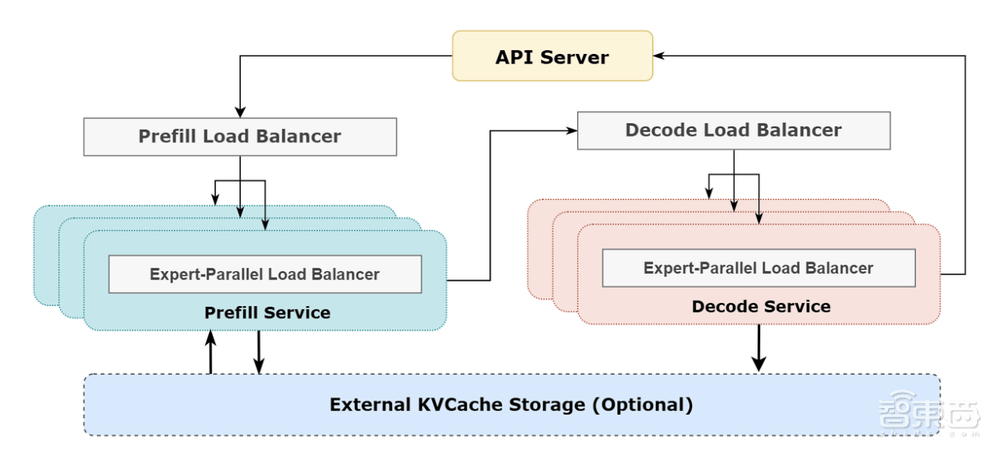
在技术层面,DeepSeek详细介绍了其DeepSeek-V3/R1推理系统的优化策略。为了实现更高的吞吐量和更低的延迟,研究团队采用了跨节点的专家并行(EP)技术。通过EP,系统能够增大batch size,将通信延迟隐藏在计算之后,并执行负载均衡,以应对EP带来的系统复杂性挑战。
据悉,DeepSeek的V3和R1服务均使用了H800 GPU,并保持了与训练阶段一致的精度,以确保服务效果。在高峰时段,DeepSeek会跨所有节点部署推理服务,而在低负载的夜间时段,则会减少推理节点,将资源分配给研究和训练任务。
在统计周期内,DeepSeek的V3和R1服务处理了608B的总输入Token,其中342B Token(56.3%)命中了KVCache硬盘缓存。总输出Token为168B,平均输出速度为每秒20-22 tps。每个H800节点在预填充(prefill)期间提供了约73.7k token/s输入的平均吞吐量,在解码(decode)期间则提供了约14.8k token/s输出的平均吞吐量。
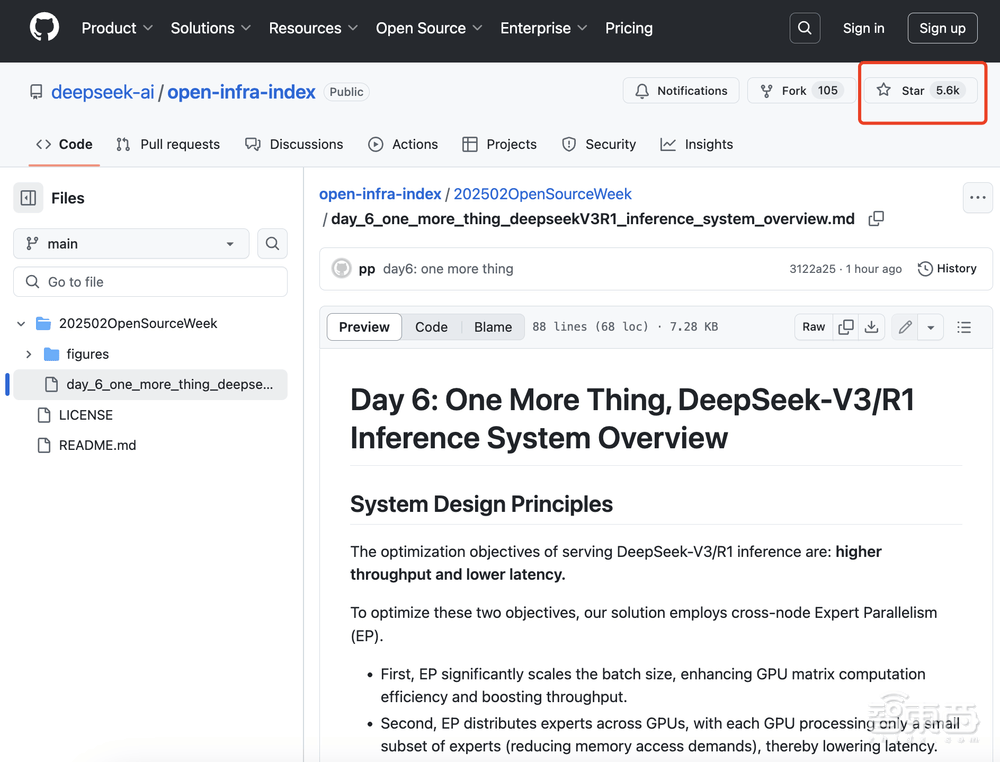
面对EP带来的系统复杂性,DeepSeek采取了三大策略来应对。首先,利用EP增大batch size,以提高GPU矩阵计算的效率。其次,将通信延迟隐藏在计算之后,通过双batch重叠等技术手段来掩盖通信开销,提高整体吞吐。最后,通过精细的负载均衡策略,确保每个GPU的计算负载和通信负载尽可能均衡,避免性能瓶颈。
DeepSeek的这一系列技术优化和财务透明度展示,不仅展示了其在AI开源领域的领先地位,也引发了业界对于AI服务成本和盈利模式的深入讨论。许多网友在评论区纷纷表示,DeepSeek的定价策略相较于OpenAI等竞争对手更具竞争力,甚至有人戏称OpenAI的定价“被抢劫”了。
DeepSeek的开源精神和财务透明度,无疑为AI行业的发展注入了新的活力。未来,随着AI技术的不断进步和应用场景的不断拓展,我们有理由相信,将会有更多像DeepSeek这样的优秀企业涌现出来,推动AI行业的持续繁荣。