在人工智能领域,一场关于具身智能的革命正在悄然进行。近日,两大创新成果相继亮相,引发了业界的广泛关注。Figure公司推出的Helix模型,以其分层架构实现了高频控制与高泛化能力的双重突破。几乎同时,中国的灵初智能团队也不甘落后,发布了基于强化学习的Psi R0.5模型,距离其前作Psi R0的问世仅仅相隔两个月。
Psi R0.5不仅在复杂场景的泛化性、灵巧性、思维链(CoT)以及长程任务能力上实现了显著提升,更在数据利用效率上展现了惊人的实力。据透露,完成泛化抓取训练所需的数据量仅为Helix的0.4%,这一数据无疑在全球范围内树立了泛化灵巧操作与训练效率的新标杆。
灵初智能团队还连续发布了四篇高质量论文,详细阐述了团队在高效泛化抓取、堆叠场景物品检索、利用外部环境配合抓取以及VLA安全对齐方面的最新研究成果。这些论文不仅展示了中国团队在具身智能领域的强大实力,更为全球研究者提供了宝贵的参考。
Psi R0.5的路径演进图清晰地展示了其从初步构想到最终实现的整个历程。其中,DexGraspVLA作为首个用于灵巧手通用抓取的VLA框架,通过少量的训练即可在多变环境下智能涌现出灵巧操作能力,其表现令人瞩目。
DexGraspVLA框架融合了视觉、语言和动作三个层次,高层规划由预训练的大型视觉语言模型实现,可理解多样化指令并自主决定抓取策略;低层控制器则通过实时视觉反馈闭环掌握目标物体,智能涌现出灵巧操作能力。整个框架的核心在于将多样化的图像输入数据通过现有的Foundation Model转换成Domain-invariance的表征,并端到端地训练下层控制模型。
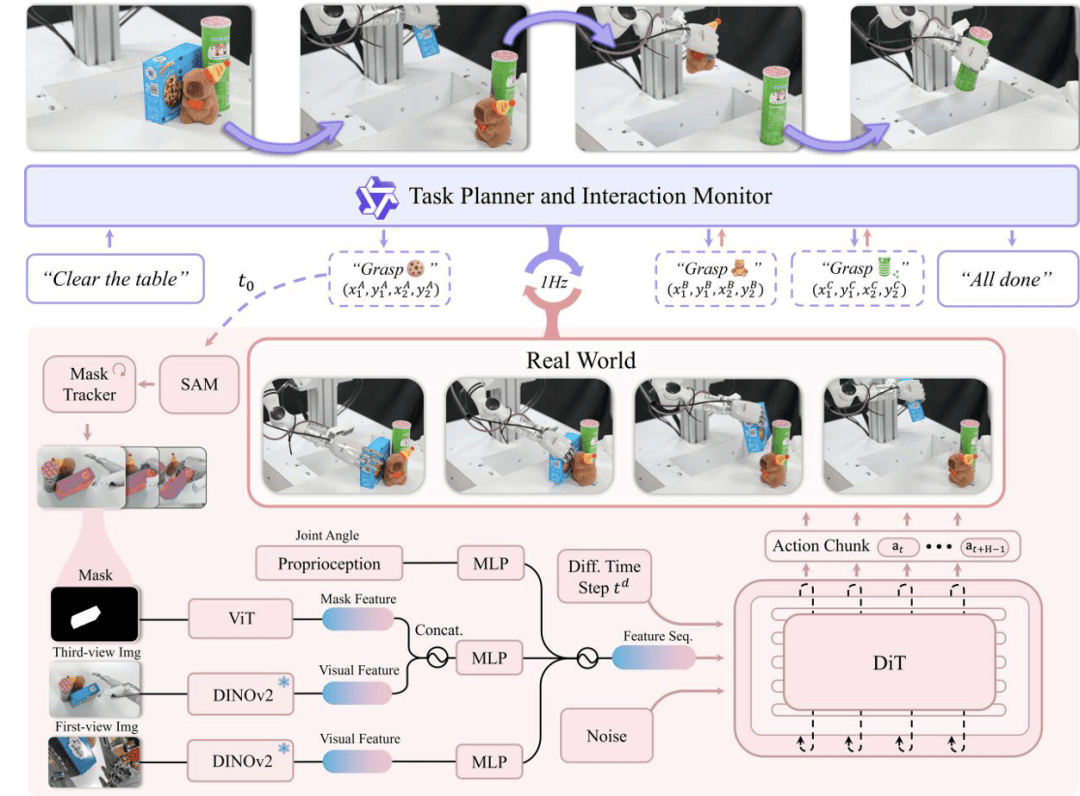
实验结果显示,灵初智能仅使用了约2小时的灵巧手抓取数据,便成功泛化到上千种不同物体、位置、堆叠、灯光和背景下进行抓取。这一数据量仅为Figure的0.4%,数据利用效率提高了250倍。DexGraspVLA不仅能够根据语言指令分辨出目标物体并处理堆叠场景下的目标物体检索与抓取,还拥有快速的抓取速度、闭环姿态矫正与重抓取能力以及长程推理能力。
灵初智能还开发了一套基于强化学习的物体检索策略——Retrieval Dexterity,解决了堆叠场景中物体检索识别效率低的问题。该策略在仿真环境中进行大规模训练,随后将训练结果零样本迁移至现实机器人和复杂环境中,实现了从杂乱堆叠物体中快速取出目标物体的目标。
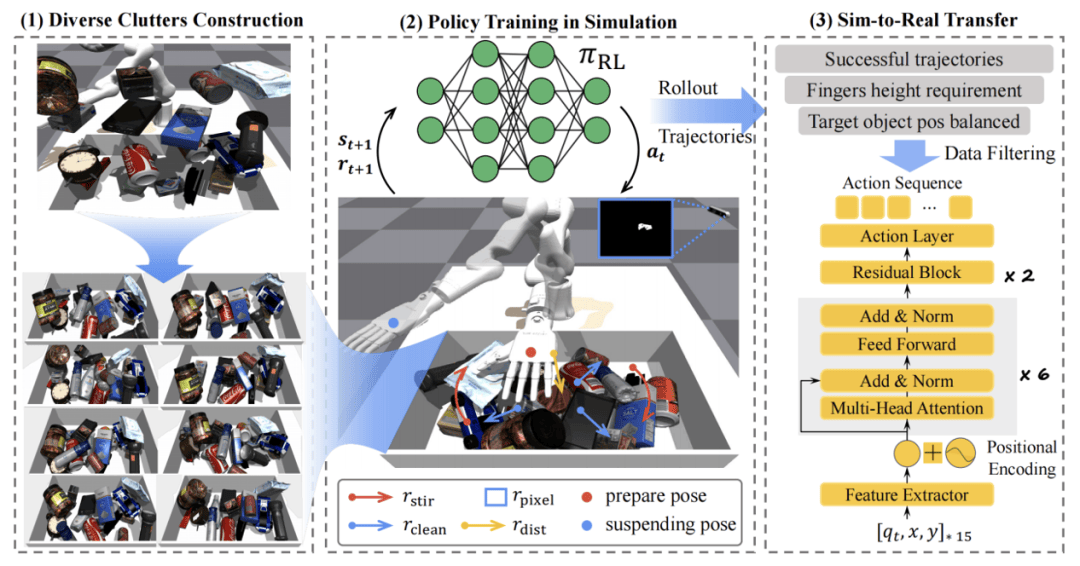
Retrieval Dexterity不仅在训练过的物体上表现出色,还能将检索能力泛化到未见过的新物体上。与人为设定的动作相比,该方法在所有场景中平均减少了38%的操作步骤。同时,灵初智能还推出了ExDex方案,利用外部灵巧性抓取那些无法直接抓取的物体。通过强化学习,ExDex能够自主制定策略,借助周围环境完成抓取任务。
最后,灵初智能与北京大学PAIR-Lab团队携手推出了具身安全模型SafeVLA。该模型通过安全对齐技术,让机器人在复杂场景中安全高效地执行任务。SafeVLA不仅关注任务的完成,更将人类安全放在首位。在引入约束马尔可夫决策过程(CMDP)范式后,SafeVLA在安全性和任务执行方面均取得了突破性进展。
SafeVLA在12个分布外(OOD)实验中表现出色,面对光照、材质变化和复杂环境扰动时始终稳定发挥。这一成果不仅证明了SafeVLA在平衡安全与效率方面的卓越能力,更为人机交互的未来提供了更加安全可靠的解决方案。