在科技巨头的版图中,人工智能(AI)正逐渐成为不可忽视的核心驱动力。从财报亮点到市场利好消息,AI的身影无处不在,引领着行业的新风向。
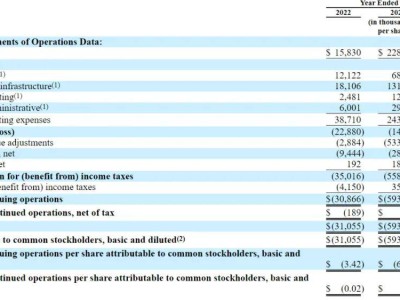
百度近期的财报便是一个生动的例子,尽管整体业绩喜忧参半,但AI无疑是其中的高光时刻。文心大模型的日均调用量实现了惊人的增长,一年间激增33倍,达到16.5亿次。同时,百度文库也凭借超过4000万的付费用户,稳居全球第二、中国第一的宝座。
阿里巴巴同样在AI领域大放异彩。先是其开源大模型通义千问(Qwen)受到DeepSeek热潮的带动而备受瞩目,随后发布的Qwen2.5-Max模型更是被誉为性能超越DeepSeek V3。更令人瞩目的是,阿里与苹果在AI业务上的合作,这一消息直接推动了其股价的大幅上涨。
然而,自DeepSeek出圈以来,科技巨头们在AI领域的焦虑似乎并未因成果而减少。面对一个初创团队打造的产品竟能一鸣惊人,大厂们不得不重新审视自己的战略。DeepSeek不仅收获了市场的广泛关注,其成本利润率更是高达545%(理论收益),每天的理论利润可达346万元,这无疑给大厂们带来了更大的压力。
在这种背景下,大厂们开始调整策略。一方面,它们纷纷宣布接入DeepSeek,试图通过合作来减轻竞争压力;另一方面,它们也将自家的大模型从闭源转向开源,甚至不惜牺牲C端产品的商业化路径,选择免费开放。
在DeepSeek出现之前,大厂们做AI的策略普遍是高投入、高举高打,围绕自身优势打造产品。大模型作为AI行业的基础设施,吸引了包括百度、腾讯、阿里、字节、快手等互联网大厂,以及华为等消费电子厂商和科大讯飞等智能语音厂商的竞相布局。相较于初创公司,大厂们拥有更雄厚的资金和人才储备。
从技术迭代速度和公开信息来看,大厂们的大模型在底层技术上并无根本性差异,但在入场时间、模型定位和市场策略上却各有千秋。例如,华为虽然最早布局,但其大模型主要面向产业专用方向;而百度则在通用智能大模型上率先行动,启动了文心一言大模型的邀测。
这些差异使得各家大模型在优势场景上各不相同。文心一言在长文本处理和多语种对话上表现出色,混元在社交场景更胜一筹,豆包在生成内容和精准推荐上领先,通义千问在电商推荐场景响应迅速,而盘古则以其执行速度和泛化能力高效应对大规模任务。
市场策略方面,大厂们对自身能力和行业趋势的判断各不相同。字节、快手、讯飞、华为坚持闭源策略,而百度、腾讯、阿里则选择大部分开源。在TO C应用上,百度、腾讯、阿里采取了免费路线,而字节、快手、讯飞则提供有限次数的免费额度。
开源的甜头已经被阿里所尝。根据开源AI平台Hugging Face发布的最新榜单,排名前十的开源大模型全部基于阿里通义千问的衍生模型。在TO C产品中,坚持免费的豆包在过去一年中涨势迅猛,根据AI产品榜显示,2025年1月豆包的国内月活用户数排名第一,远超其他大厂应用。
然而,大厂们在大模型整体能力上的排名仍然是一个谜。多位从业者表示,由于顶级大模型多以闭源为主,信息不完全透明,因此判断各家能力并非易事。尽管如此,弗若斯特沙利文在《2024年中国大模型能力评测》报告中仍然指出,百度文心一言、腾讯混元、阿里通义千问等大厂大模型位于第一梯队。
DeepSeek的出现促使大厂们重新审视AI战略布局,并带来了四大转变。一是从闭源到开源的重大转变。不止一位从业者指出,DeepSeek的火爆离不开其开源策略。大厂们开始倾向于通过生态绑定实现长期收益,而非单纯依赖技术保密。
二是业务重点从TO B转向“双线并行”。尽管大厂们当前盈利仍主要依赖B端,但近期很多大厂开始重视TO C应用的推广。例如腾讯加大对元宝的宣传力度,多渠道投放广告。
三是TO C应用从收费变为免费。在DeepSeek大火后,国内百度的文心一言、国外OpenAI即将推出的GPT-5都宣布将免费对用户开放。这一策略旨在拉拢更多用户,提高市场占有率。
四是从重投入到降本打价格战。DeepSeek以极低的GPU成本训练出与OpenAI GPT-4能力相当的模型,这让大厂们开始反思高投入的策略。大模型的竞争已经从“技术为先”转向为“成本+生态”。
在这四大变化中,对大厂影响最大的是开源和免费。开源面临着收益损失和技术风险,但同时也可能吸引更多的技术开发者和合作公司。免费策略则旨在快速占领C端市场,但用户对chatbot工具的忠诚度低和付费意识不强也是大厂们需要面对的挑战。
尽管如此,大厂们仍然不得不采取这些策略来应对DeepSeek引发的鲇鱼效应。在成本与生态的综合较量中,开源和免费策略成为了一把双刃剑。尽管这些措施短期内可能会降低自身收益,但大厂们为了保持竞争力,也不得不为之。