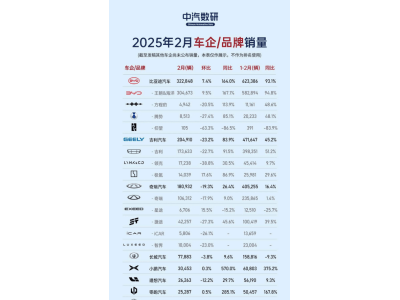
腾讯混元团队于近日宣布了一项重大进展,正式发布了图生视频模型,并慷慨地向公众开源。这一创新不仅带来了对口型与动作驱动等新颖玩法,还实现了背景音效的自动生成及2K高清视频的创作。
借助这一技术,用户只需上传一张静态图片,并简要描述希望实现的画面动态效果及镜头调度,混元图生视频模型便能将这些创意转化为生动、流畅的5秒短视频。更令人惊叹的是,它还能智能匹配合适的背景音效,为视频增添更多趣味与氛围。

混元图生视频模型还具备强大的“对口型”功能。用户只需上传人物图片,并输入想要匹配的文字或音频内容,图片中的人物便能仿佛真的在“说话”或“唱歌”。如果选择动作模板,用户还能轻松生成与模板同款的跳舞视频,为创作带来更多乐趣。
此次开源的图生视频模型,是腾讯混元团队在文生视频模型开源工作上的进一步延伸。该模型总参数量高达130亿,广泛应用于写实视频制作、动漫角色乃至CGI角色创作等多个领域。开源内容涵盖了权重、推理代码及LoRA训练代码,为开发者提供了基于混元训练专属LoRA等衍生模型的便利。
据混元开源技术报告显示,其视频生成模型展现出极高的灵活性与扩展性。图生视频与文生视频在同一数据集上进行预训练,确保了模型在保持超写实画质、流畅演绎大幅度动作及原生镜头切换等特性的同时,能够捕捉到丰富的视觉与语义信息。结合图像、文本、音频及姿态等多种输入条件,该模型实现了对生成视频的多维度精准控制。

自混元视频生成模型开源以来,其在Github平台上备受瞩目,Star数迅速攀升至8.9K以上。众多开发者自发基于社区Hunyuanvideo制作了丰富的插件与衍生模型,累计衍生版本已超过900个。而更早开源的混元DiT文生图模型,在国内外更是衍生出了多达1600多个模型版本,展现了其强大的吸引力和影响力。
目前,腾讯混元开源系列模型已全面覆盖文本、图像、视频及3D生成等多个模态,累计吸引了超过2.3万开发者在Github上的关注与Star。这一系列的开源举措,无疑为AI生成技术的发展注入了新的活力,也为开发者提供了更为广阔的创新空间。