在机器人技术的前沿探索中,一款名为智元启元大模型Genie Operator-1(简称GO-1)的创新成果近日由智元机器人公司正式发布。这款通用具身基座模型,以其独特的Vision-Language-Latent-Action(ViLLA)框架,为机器人领域带来了革命性的突破。
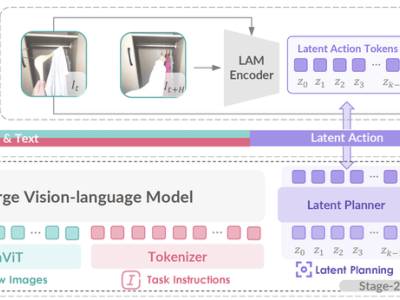
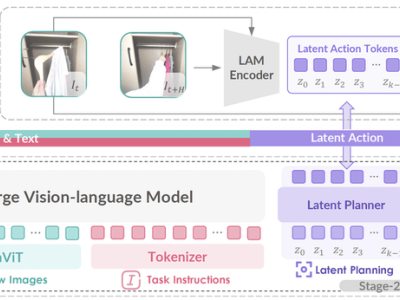
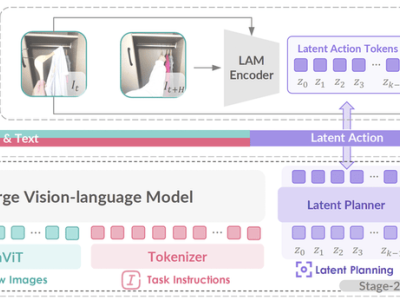
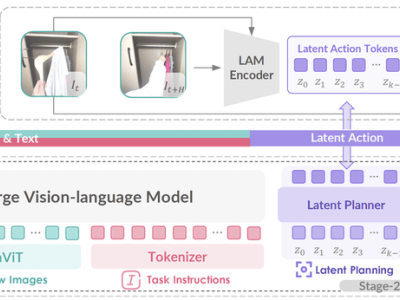
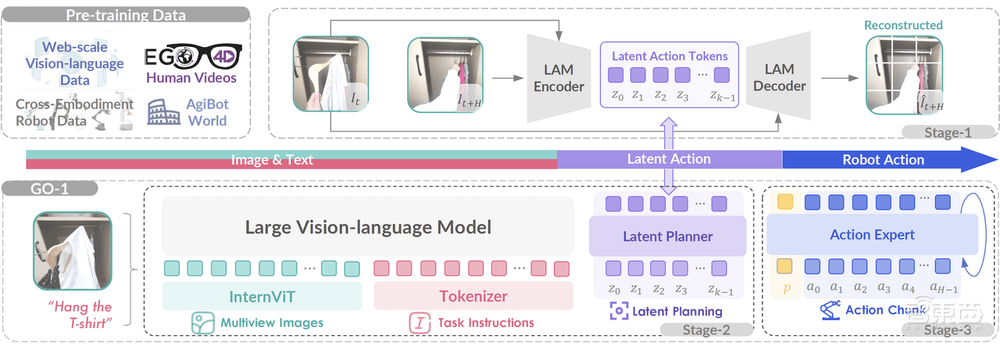
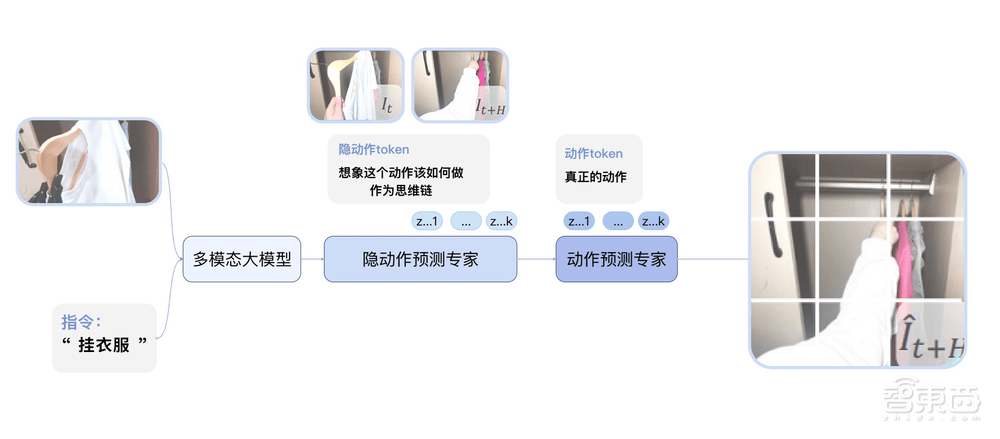
GO-1的核心在于其ViLLA框架,该框架融合了VLM(多模态大模型)与MoE(混合专家)技术。VLM作为主干网络,基于开源多模态大模型5-2B的权重,并通过互联网上的大规模纯文本和图文数据进行训练,赋予了GO-1强大的场景感知和理解能力。而MoE则包含隐动作专家模型和动作专家模型,前者利用互联网上的大规模人类操作和跨本体操作视频,使模型能够理解动作;后者则通过高质量的仿真数据和真机数据,确保模型能够精确执行动作。
GO-1展现出了多方面的卓越性能。其采训推一体化设计,使得数据采集、模型训练和模型推理能够无缝衔接。小样本快速泛化能力,让GO-1能够在极少数据甚至零样本的情况下,快速适应新场景和新任务。“一脑多形”的跨本体应用能力,意味着GO-1可以灵活迁移至不同形态的机器人上,实现快速适配。持续进化能力,则依赖于智元的数据回流系统,使模型能够从实际执行中遇到的问题数据中不断学习进步。而人类视频学习能力,则进一步增强了模型对人类行为的理解。
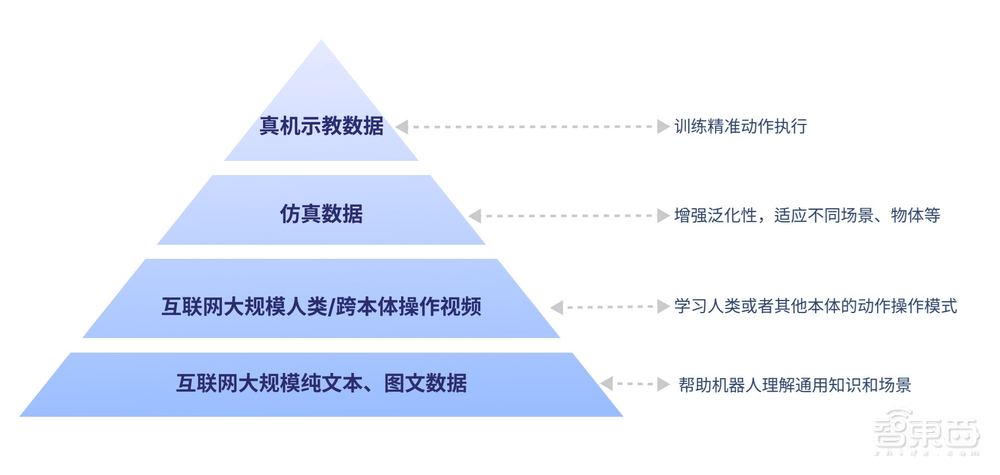
GO-1的构建基于具身领域的数字金字塔模型。底层是互联网的大规模纯文本与图文数据,为机器人提供通用知识和场景理解。上一层是人类操作/跨本体视频,帮助机器人学习动作操作模式。再上一层是仿真数据,用于增强泛化性。金字塔的顶层则是高质量的真机示教数据,确保动作的精准执行。这种全面的数据基础,使得GO-1能够轻松面对多样化的环境和物体,快速学习新的操作。
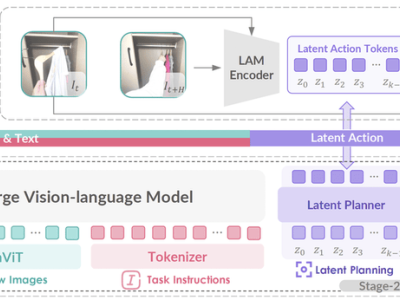
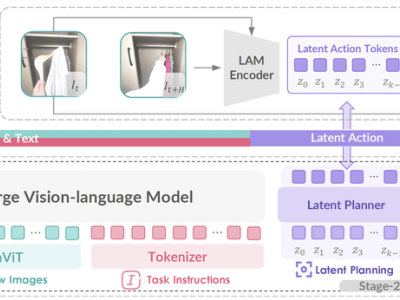
ViLLA框架的引入,使得GO-1能够将多相机的视觉信号和人类语言指令直接转化为机器人的动作执行。与Vision-Language-Action(VLA)模型相比,ViLLA通过预测隐式动作标记(Latent Action Tokens),有效弥合了图像-文本输入与机器人执行动作之间的鸿沟。例如,当用户以自然语言向机器人发出“挂衣服”的指令时,GO-1能够准确理解指令含义,并根据所学习的人类操作视频和仿真数据,规划出挂衣服的步骤,并最终精准完成任务。
GO-1的应用场景广泛。在家庭环境中,它可以帮忙倒水、烤吐司等日常任务。在商业活动中,它可以负责检票、发放物料等工作。在商务会议中,面对人类的各种语音指令,GO-1都能迅速响应并执行。GO-1的数据回流能力使其能够持续进化,从遇到的问题数据中不断学习和改进。


GO-1的出现,标志着具身智能正加速迈向通用化、开放化与智能化。它解决了具身智能面临的诸多挑战,如场景和物体泛化能力不足、语言理解能力欠缺、新技能学习缓慢以及跨本体部署困难等。随着GO-1在更多场景中的应用,机器人将逐渐替代人类完成更多工作生活中的任务,从家庭到办公、从商业到工业,通用具身基座大模型都将展现出其强大的潜力和价值。