近期,豆包大模型团队低调推出的Seedream2.0图像生成模型,在业界引发了广泛关注。这款模型不仅在中英文双语理解与文字渲染方面表现突出,还已经在豆包和即梦等应用中得以应用。随着该模型的技术细节在arXiv平台上的正式公布,其背后的创新技术也得以公之于众。
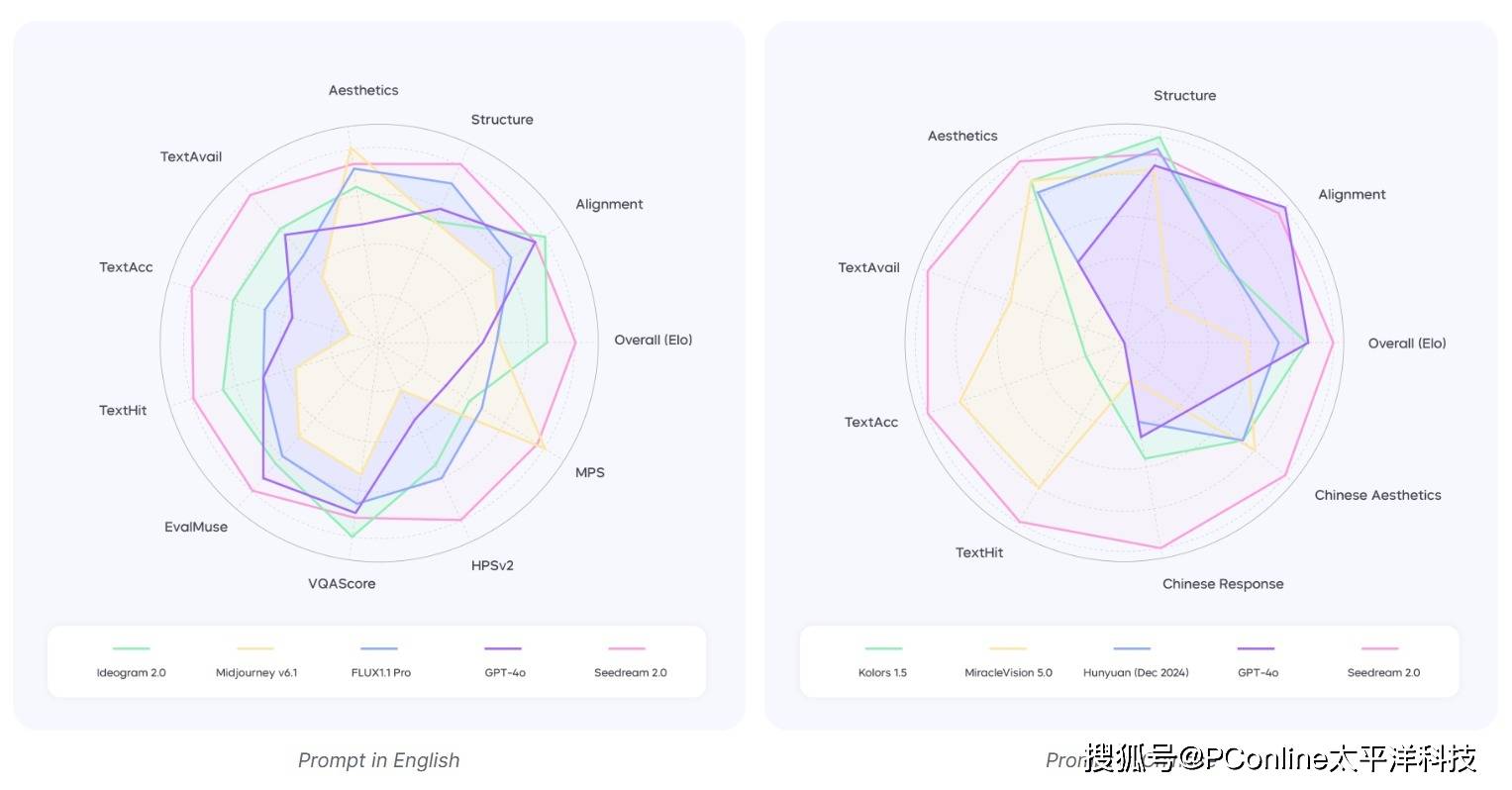
相较于Midjourney等主流图像生成模型,Seedream2.0的显著优势在于其双语解析和文字渲染能力。它不仅能够直接理解中文提示词进行图像渲染,还能精准地输出中英文文字。在一系列针对主流文生图模型的测试中,Seedream2.0在多个维度上均超越了当前最先进的模型,特别是在中文文化细节和文本渲染方面,其表现尤为卓越。
通过几个实际案例,我们可以更加直观地感受到Seedream2.0的强大能力。例如,在一张使用中文Prompt生成的照片中,一只橙色虎斑猫特写镜头下,猫咪抬起前爪,眼神中充满好奇,仿佛即将采取行动。背景是蓝天白云与耀眼阳光,前景则是绿色草地,太阳逆光效果营造出高对比度,整体风格超写实,景深效果自然,背景还带有轻微的动态模糊。这些细节的处理都极为到位,使得整个画面看起来栩栩如生。
Seedream2.0在汉字渲染方面也展现出了不俗的实力。使用该模型渲染的汉字“猫”,并添加毛笔字效果,虽然笔画上存在一些不符合书写逻辑的地方,但整体上仍然能够清晰地辨认出是“猫”字,且国风水墨画的氛围感十足。
Seedream2.0之所以能够实现如此出色的图像渲染效果,离不开其先进的扩散式Transformer架构。该架构中的每个Transformer模块都包含一个自注意力层,能够同时处理图像和文本信息。针对图像和文本的不同特性,模型还采用了不同的多层感知机(MLP)进行处理,并通过自适应层归一化来调节每个注意力和MLP层。
在文本编码方面,Seedream2.0通过将文本和图像配对的数据用于微调大型语言模型(LLM),显著增强了其双语处理能力和理解复杂指令的能力。同时,为了准确编码渲染文本的字形内容,模型还采用了ByT5字形对齐模型,确保与文本提示的一致性。
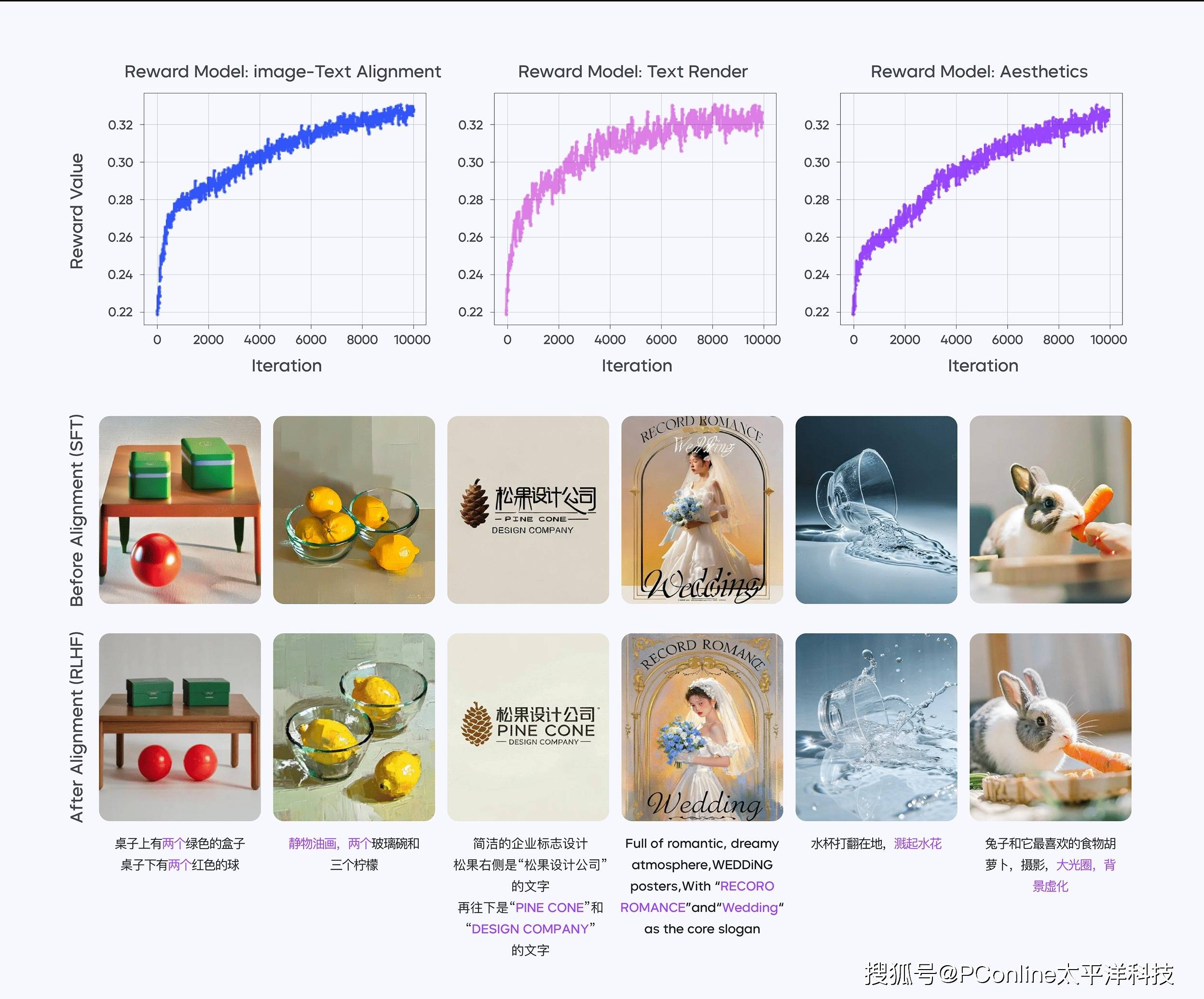
在模型训练过程中,Seedream2.0团队采用了多阶段的方法。首先进行继续训练(CT)和监督微调(SFT),以提升模型的美学效果。随后,通过自研的奖励模型和反馈学习算法进行人类反馈对齐(RLHF),显著改善了模型在各方面的整体表现。团队还利用精调的大型语言模型(LLM)进行提示工程(PE),进一步提高了模型在美学和多样性方面的表现。最后,开发了精修模型以提高基础模型生成图像的分辨率,并修正一些细微的结构性错误。
特别是在RLHF阶段,Seedream2.0团队引入了专为扩散模型设计的优化过程,包括偏好数据、奖励模型和反馈学习算法。这一阶段在提升模型的图文一致性、美学效果、结构正确性和文本渲染等方面发挥了至关重要的作用。
自Seedream2.0发布以来,用户普遍反映该模型在中英双语解析、图像细节呈现和文字渲染方面表现出色。技术细节的公开进一步验证了其在数据处理和训练优化上的先进性,也为广大中文用户提供了更多信心。对于广大中文用户而言,Seedream2.0无疑是一款比Midjourney更加贴合需求的国产大模型。